
Lab 1: Linear models#
Part 2: Classification#
The Fashion-MNIST dataset contains 70,000 images of Zalando fashion products, classified into 10 types of clothing, each represented by 28 by 28 pixel values. We’s see how well we can classify these with linear models. Let’s start with looking at our data:
# Auto-setup when running on Google Colab
if 'google.colab' in str(get_ipython()):
!pip install openml
# General imports
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import openml as oml
from matplotlib import cm
# Hide convergence warning for now
import warnings
from sklearn.exceptions import ConvergenceWarning
warnings.filterwarnings("ignore", category=ConvergenceWarning)
# Hiding all warnings. Not recommended, just for compilation.
if not sys.warnoptions:
warnings.simplefilter("ignore")
os.environ["PYTHONWARNINGS"] = "ignore"
# Download FMINST data. Takes a while the first time.
fmnist = oml.datasets.get_dataset(40996)
X, y, _, _ = fmnist.get_data(target=fmnist.default_target_attribute);
fmnist_classes = {0:"T-shirt/top", 1: "Trouser", 2: "Pullover", 3: "Dress", 4: "Coat", 5: "Sandal",
6: "Shirt", 7: "Sneaker", 8: "Bag", 9: "Ankle boot"}
# Take some random examples, reshape to a 32x32 image and plot
from random import randint
fig, axes = plt.subplots(1, 5, figsize=(10, 5))
for i in range(5):
n = randint(0,70000)
axes[i].imshow(X.values[n].reshape(28, 28), cmap=plt.cm.gray_r)
axes[i].set_xlabel((fmnist_classes[int(y.values[n])]))
axes[i].set_xticks(()), axes[i].set_yticks(())
plt.show();

Exercise 1: A quick benchmark#
First, we’ll try the default Logistic Regression and Linear SVMs. Click the links to read the documentation. We’ll also compare it to k-Nearest Neighbors as a point of reference. To see whether our models are overfitting, we also evaluate the training set error. This can be done using cross_validate instead of cross_val_scores.
For now we are just interested in a quick approximation, so we don’t use the full dataset for our experiments. Instead, we use 10% of our samples:
from sklearn.model_selection import train_test_split, cross_validate
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.neighbors import KNeighborsClassifier
# Take a 10% stratified subsample to speed up experimentation
Xs, _, ys, _ = train_test_split(X,y, stratify=y, train_size=0.1)
With this small sample of our data we can now train and evaluate the three classifiers.
Exercise 1.1#
Implement a function below which evaluates each classifier passed into it on the given data, and then returns both the train and test scores of each as a list. You are allowed to import additional functions from whichever module you like, but you should be able to complete the function with cross_validate function and standard Python built-ins. Below the function you will find example output.
def evaluate_learners(classifiers, X, y):
""" Evaluate each classifier in 'classifiers' with cross-validation on the provided (X, y) data.
Given a list of scikit-learn classifiers [Classifier1, Classifier2, ..., ClassifierN] return two lists:
- a list with the scores obtained on the training samples for each classifier,
- a list with the test scores obtained on the test samples for each classifier.
The order of scores should match the order in which the classifiers were originally provided. E.g.:
[Classifier1 train score, ..., ClassifierN train score], [Classifier1 test score, ..., ClassifierN test score]
"""
pass
# # Example output:
# train_scores, test_scores = ([[0.92 , 0.924, 0.916, 0.917, 0.921], # Classifier 1 train score for each of 5 folds.
# [0.963, 0.962, 0.953, 0.912, 0.934], # Classifier 2 train score for each of 5 folds.
# [0.867, 0.868, 0.865, 0.866, 0.866]], # Classifier 3 train score for each of 5 folds.
# [[0.801, 0.811, 0.806, 0.826, 0.804], # Classifier 1 test score for each of 5 folds.
# [0.766, 0.756, 0.773, 0.756, 0.741], # Classifier 2 test score for each of 5 folds.
# [0.804, 0.814, 0.806, 0.821, 0.806]]) # Classifier 3 test score for each of 5 folds.
Solution#
# MODEL IMPLEMENTATION:
def evaluate_learners(classifiers, X, y):
""" Evaluate each classifier in 'classifiers' with cross-validation on the provided (X, y) data.
Given a list of classifiers [Classifier1, Classifier2, ..., ClassifierN] return two lists:
- a list with the scores obtained on the training samples for each classifier,
- a list with the test scores obtained on the test samples for each classifier.
The order of scores should match the order in which the classifiers were originally provided. E.g.:
[Classifier1 train scores, ..., ClassifierN train scores], [Classifier1 test scores, ..., ClassifierN test scores]
"""
# Evaluate with 3-fold cross-validation.
xvals = [cross_validate(clf, X, y, return_train_score= True, n_jobs=-1) for clf in classifiers]
train_scores = [x['train_score'] for x in xvals]
test_scores = [x['test_score'] for x in xvals]
return train_scores, test_scores
Exercise 1.2#
Call the function you created with a Logistic Regression, Linear SVM, and k-Nearest Neighbors Classifier.
Store the return values in the variables train_scores and test_scores. Then, run the code given below to produce a plot visualizing the scores.
# Dummy code. Replace with the actual classifiers and scores
classifiers = [LogisticRegression()]
train_scores, test_scores = [[0.6,0.7,0.8]], [[0.5,0.6,0.7]]
Solution#
classifiers = [LogisticRegression(), LinearSVC(), KNeighborsClassifier()]
train_scores, test_scores = evaluate_learners(classifiers, Xs, ys)
# Plot a bar chart of the train and test scores of all the classifiers, including the variance as error bars
fig, ax = plt.subplots()
width=0.3
ax.barh(np.arange(len(train_scores)), np.mean(test_scores, axis=1), width,
yerr= np.std(test_scores, axis=1), color='green', label='test')
ax.barh(np.arange(len(train_scores))-width, np.mean(train_scores, axis=1), width,
yerr= np.std(train_scores, axis=1), color='red', label='train')
for i, te, tr in zip(np.arange(len(train_scores)),test_scores,train_scores):
ax.text(0, i, "{:.4f} +- {:.4f}".format(np.mean(te),np.std(te)), color='white', va='center')
ax.text(0, i-width, "{:.4f} +- {:.4f}".format(np.mean(tr),np.std(tr)), color='white', va='center')
ax.set(yticks=np.arange(len(train_scores))-width/2, yticklabels=[c.__class__.__name__ for c in classifiers])
ax.set_xlabel('Accuracy')
ax.legend(bbox_to_anchor=(1.05, 1), loc=2)
plt.show()

Exercise 1.3#
Interpret the plot. Which is the best classifier? Are any of the models overfitting? If so, what can we do to solve this? Is there a lot of variance in the results?
Solution#
k-NN and LogisticRegression have the best cross-validated test set performance. The linear SVM performs noticeably worse. Both linear models have a big difference between training set accuracy and test set accuracy. This indicates that both linear models are likely overfitted and need to be regularized. The standard deviation of the results is very small: the error bars are hardly noticeable.
Exercise 2: Regularization#
We will now tune these algorithm’s main regularization hyperparameter: the misclassification cost in SVMs (C), the regularization parameter in logistic regression (C), and the number of neighbors (n_neighbors) in kNN. We expect the optimum for the C parameters to lie in \([10^{-12},10^{12}]\) and for n_neighbors between 1 and 50. C should be varied on a log scale (i.e. [0.01, 0.1, 1, 10, 100]) and k should be varied uniformly (i.e. [1,2,3,4]).
Exercise 2.1#
Vary the regularization parameters in the range given above and, for each classifier, create a line plot that plots both the training and test score for every value of the regularization hyperparameter. Hence, you should produce 3 plots, one for each classifier. Use the default 5-fold cross validation for all scores, but only plot the means.
Hints:
Think about the time complexity of these models. Trying too many hyperparameter values may take too much time.
You can make use of numpy’s logspace, geomspace, and linspace functions.
You can use matplotlib’s default plot function to plot the train and test scores.
You can manually loop over the hyperparameter ranges, or you can already check out scikit-learn’s GridSearchCV function to save some programming. We’ll see it again later in the course.
Solution#
from sklearn.model_selection import GridSearchCV
param_c = {'C': np.logspace(-12, 12, num=22)}
param_k = {'n_neighbors': np.geomspace(1, 60, num=12, dtype=int)[1:]}
grids = [param_c, param_c, param_k]
grid_searches = [GridSearchCV(clf, grid, n_jobs=-1, cv=3, return_train_score=True).fit(Xs, ys) for clf,grid in zip(classifiers,grids)]
# Generic plot for 1D grid search
# grid_search: the result of the GridSearchCV
# param_name: the name of the parameter that is being varied
def plot_tuning(grid_search, param_name, ax):
ax.plot(grid_search.param_grid[param_name], grid_search.cv_results_['mean_test_score'], marker = '.', label = 'Test score')
ax.plot(grid_search.param_grid[param_name], grid_search.cv_results_['mean_train_score'], marker = '.', label = 'Train score')
ax.set_ylabel('score (ACC)')
ax.set_xlabel(param_name)
ax.legend()
ax.set_xscale('log')
ax.set_title(grid_search.best_estimator_.__class__.__name__)
bp, bs = grid_search.best_params_[param_name], grid_search.best_score_
ax.text(bp,bs," C:{:.2E}, ACC:{:.4f}".format(bp,bs))
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15,5))
for grid_search, param, ax in zip(grid_searches,['C','C','n_neighbors'],axes):
plot_tuning(grid_search, param, ax)
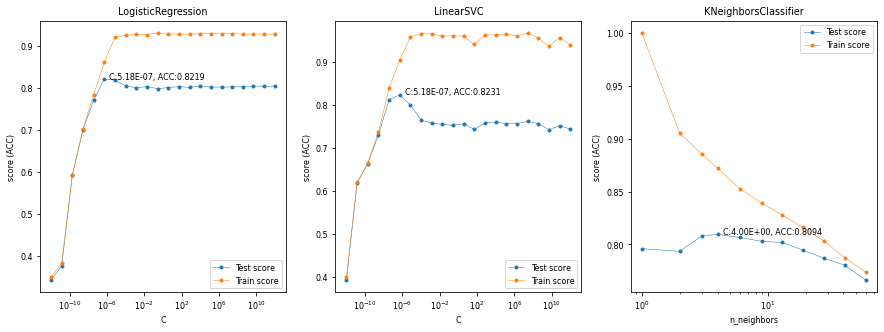
Exercise 2.2#
Interpret the plots. When are the methods underfitting? When are they overfitting? How sensitive are they to the regularization hyperparameter?
Solution#
We find that, when properly regularized, the linear models both outperform kNN, and that linear SVMs seem to do slighty better of these two. Logistic regression underfits for small values of C, reaches an optimum around C=1e-7, and then starts overfitting. The linear SVM behaves the same way, but with an optimum around C=1e-8. The kNN overfits for small numbers of neighbors, reaches an optimum around n_neighbors=4, and then starts underfitting gradually. Note that these results were obtained on a 10% subsample. Results may be different when we optimize our models on the entire datset.
Exercise 3: Interpreting misclassifications#
Chances are that your models are not yet perfect. It is important to understand what kind of errors it still makes. Let’s take a closer look at which instances are misclassified and which classes are often confused.
Train the logistic regression model with C=1e-7. Train the model on a training set, and make predictions for a test set (both sets should be sampled from our 10% subsample).
# Create a stratified train-test split on a sample
X_train, X_test, y_train, y_test = train_test_split(Xs,ys, stratify=ys, random_state=0)
Exercise 3.1#
Train the classifier as described above, obtain the predictions y_pred on the test set, and identify all the misclassified samples misclassified_samples. Then, run the visualization code below to study the misclassifications
# Implement the code to obtain the actual predictions on the test set
y_pred = list(y_test) # dummy values, replace y_test with the actual predictions
# Implement the code to obtain the indices of the misclassified samples
# Example output:
# misclassified_samples = [ 11, 12, 14, 23, 30, 34, 39, 46, 50, 52, 55]
misclassified_samples = [0,1,2,3,4] # dummy values
Solution#
# model implementation:
model = LogisticRegression(C=1e-7).fit(X_train,y_train)
y_pred = model.predict(X_test)
misclassified_samples = np.nonzero(y_pred != list(y_test))[0]
# Visualize the (first five) misclassifications, together with the predicted and actual class
fig, axes = plt.subplots(1, 5, figsize=(10, 5))
for nr, i in enumerate(misclassified_samples[:5]):
axes[nr].imshow(X_test.values[i].reshape(28, 28), cmap=plt.cm.gray_r)
axes[nr].set_xlabel("Predicted: %s,\n Actual : %s" % (fmnist_classes[int(y_pred[i])],fmnist_classes[int(y_test.values[i])]))
axes[nr].set_xticks(()), axes[nr].set_yticks(())
plt.show();

Exercise 3.2#
Interpret the results. Are these misclassifications to be expected?
Solution#
Some of these seem quite common mistakes, such as confusing shirts and coats. The images are quite coarse so there may not be enough detail. Others, like misclassifying a dress for a t-shirt, seem more curious.
Exercise 3.3.#
Run the code below on your results to draw the complete confusion matrix and get more insight on the systematic misclassifications of your model. A confusion matrix shows the amount of examples in for each pair of true and predicted classes. Interpret the results. Does your model produce certain types of error more often than other types?
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
fig, ax = plt.subplots()
im = ax.imshow(cm)
ax.set_xticks(np.arange(10)), ax.set_yticks(np.arange(10))
ax.set_xticklabels(list(fmnist_classes.values()), rotation=45, ha="right")
ax.set_yticklabels(list(fmnist_classes.values()))
ax.set_ylabel('True')
ax.set_xlabel('Predicted')
for i in range(100):
ax.text(int(i/10),i%10,cm[i%10,int(i/10)], ha="center", va="center", color="w")

Solution#
We see that some categories are much easier to predict than others. For instance, trousers and bags are almost always predicted correctly, while sneakers are occasionally confused with sandals or boots. Shirts, on the other hand, are misclassified close to half of the time, predominantly confused with t-shirts, pullovers, and coats.
Exercise 4: Interpreting model parameters#
Finally, we’ll take a closer look at the model parameters, i.e. the coefficients of our linear models. Since we are dealing with 28x28 pixel images, we have to learn 784 coefficients. What do these coefficients mean? We’ll start by plotting them as 28x28 pixel images.
Exercise 4.1#
Train a Logistic Regression model and a Linear SVM using their tuned hyperparameters from exercise 2.
When in doubt, use C=1e-7 for LogReg and C=1e-8 for the SVM.
Pass the trained model to the provided plotting function. Interpret the results in detail.
Why do you get multiple plots per model? What do the features represent in your data.
Does it seems like the models pay attention to the right features?
Do you models seem to ignore certain features? Do you observe differences in quality between the different classes? Do you observe any differences between the models?
# Plots the coefficients of the given model as 28x28 heatmaps.
# The `name` attribute is optional, it is simply a title for the produced figure
def plot_coefficients(model, name=None):
fig, axes = plt.subplots(1,10,figsize=(20,2))
fig.suptitle(name if name else model.__class__.__name__)
for i, ax in enumerate(axes):
m = ax.imshow(model.coef_[i].reshape(28,28))
ax.set_xlabel(fmnist_classes[i])
ax.set_xticks(()), ax.set_yticks(())
fig.colorbar(m, ax=axes.ravel().tolist())
Solution#
plot_coefficients(LogisticRegression(C=1e-7).fit(X_train,y_train))
plot_coefficients(LinearSVC(C=1e-8).fit(X_train,y_train))


Remember that linear models are typically binary classifiers. They will solve multi-class problems in a one-vs-all approach. Hence, for a 10-class problem, they will build 10 models, each one trained to predict whether an instance is from a specific class or not. This leads to 10 sets of 784 trained coefficients. Above, we plot them as 28x28 matrices, such that each coefficient is plotted at the location of their corresponding pixel value.
Very high values for coefficients (bright pixels in the images) or very low values (dark pixels in the images) cause the corresponding pixel values to have a large effect on the final prediction. In other words, the very bright and very dark pixels in the images are the pixels that the model is mainly ‘looking’ at to make a prediction. We can easily recognize the shapes of the fashion items for each class. For instance, for classifying a t-shirt (yes or no), the model will blow up the pixel values near the edges of the shirt, and especially near the shoulders, while it will suppress the background pixel values near the outlines of the shirt. If the sum of all these values is large, it will likely lead to a positive prediction for that class.
We can also see that some classes are less defined than others in these images, and these are typically the classes which are easily confused for other classes.
Both models seem to focus on the same coefficients, yielding very similar images, yet smoother for the SVM. Moreover, the Linear SVM uses much smaller coefficients.
Finally, out of curiosity, let’s see the result of underfitting and overfitting on the learned coefficients:
Exercise 4.2#
Repeat the previous exercise, but now only with logistic regression. In addition to a tuned version, also add a model that overfits a lot and one that underfits a lot. Interpret and explain the results.
Solution#
plot_coefficients(LogisticRegression(C=1e-12).fit(X_train,y_train),"Underfitting logistic regression")
plot_coefficients(LogisticRegression(C=1e-7).fit(X_train,y_train),"Good fit logistic regression")
plot_coefficients(LogisticRegression(C=1e+10).fit(X_train,y_train),"Overfitting logistic regression")



In the case that we underfit the logistic regression model, we see that the model has very strong believes of the shapes. This is evidenced by the many extreme weights (very bright or very dark). In the underfit model a t-shirt has, in addition to the short sleeves, a heigh weight for the bottom of the t-shirt. With the better tuned model (in the middle), the importance of the overall shape is still present, but the emphasis is on just the short sleeves.
If we overfit the model, it pays attention to seemingly random pixels, including pixels that are simply background pixels. The coefficients are much higher (or much more negative), meaning that the model can yield different predictions for only slight variations in the input pixel value.
We can expect similar behavior from under- or overfitted linear SVMs.