
Lab 7: Deep Learning for text#
# General imports
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow.keras as keras
3 examples#
Binary classification (of movie reviews)
Multiclass classification (of news topics)
Regression (of house prices)
We’ll use the Keras API, integrated in TensorFlow 2.
Examples from Deep Learning with Python, by François Chollet
Binary classification#
Dataset: 50,000 IMDB reviews, labeled positive (1) or negative (0)
Included in Keras, with a 50/50 train-test split
Each row is one review, with only the 10,000 most frequent words retained
Each word is replaced by a word index (word ID)
Hence, this data is already preprocessed. If you want to start from raw text data, you need to Tokenize the text first.
from tensorflow.keras.datasets import imdb
# Download IMDB data with 10000 most frequent words
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print("Encoded review: ", train_data[0][0:10])
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
print("Original review: ", ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]][0:10]))
Encoded review: [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]
Original review: ? this film was just brilliant casting location scenery story
The data is encoded as sequences of word IDs, so we need to properly encode them first. We could use a word embedding (see later), or TF-IDF, but for now we will just one-hot-encode them. For instance, if the text contains word ‘14’, the 14th feature should be ‘1’. The following is a helper function for doing this. We also need to convert the target label to floats, since they need to be compared with the numerical outputs of the neural net.
# Custom implementation of one-hot-encoding
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # set specific indices of results[i] to 1s
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
print("Encoded review: ", train_data[0][0:10])
print("One-hot-encoded review: ", x_train[0][0:10])
# Convert 0/1 labels to float
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print("Label for the first review: ", y_train[0])
Encoded review: [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]
One-hot-encoded review: [0. 1. 1. 0. 1. 1. 1. 1. 1. 1.]
Label for the first review: 1.0
Building the network#
We can solve this problem using a network of Dense layers and the ReLU activation function.
For now, we start with 2 layers of 16 hidden units each
Output layer: since this is a binary classification problem, we will use a single unit with sigmoid activation function
Close to 1: positive review, close to 0: negative review
The loss function should be binary cross-entropy.
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
Metal device set to: Apple M1 Pro
2022-02-02 16:25:41.951585: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-02-02 16:25:41.951739: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)
Note: for more control, you can explictly create the optimizer, loss, and metrics. You can also change hyperparameters such as the SGD learning rate.
from tensorflow.keras import optimizers
from tensorflow.keras import losses
from tensorflow.keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
Model selection#
To tune the hyperparameters, split the training data into a training and validation set.
Train the neural net and track the loss after every iteration on the validation set
This is returned as a
Historyobject by thefit()functionThe
Historyobject contains the loss, accuracy, validation loss, and validation accuracy for every epoch.
We start with 20 epochs in minibatches of 512 samples
x_val, partial_x_train = x_train[:10000], x_train[10000:]
y_val, partial_y_train = y_train[:10000], y_train[10000:]
history = model.fit(partial_x_train, partial_y_train,
epochs=20, batch_size=512, verbose=1,
validation_data=(x_val, y_val))
2022-02-02 16:25:42.782619: W tensorflow/core/platform/profile_utils/cpu_utils.cc:128] Failed to get CPU frequency: 0 Hz
2022-02-02 16:25:42.945021: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
Epoch 1/20
30/30 [==============================] - 2s 41ms/step - loss: 0.5020 - accuracy: 0.7869 - val_loss: 0.3738 - val_accuracy: 0.8746
Epoch 2/20
1/30 [>.............................] - ETA: 0s - loss: 0.3289 - accuracy: 0.9082
2022-02-02 16:25:44.153087: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
30/30 [==============================] - 0s 15ms/step - loss: 0.2986 - accuracy: 0.9037 - val_loss: 0.3359 - val_accuracy: 0.8650
Epoch 3/20
30/30 [==============================] - 0s 13ms/step - loss: 0.2214 - accuracy: 0.9287 - val_loss: 0.2797 - val_accuracy: 0.8905
Epoch 4/20
30/30 [==============================] - 0s 14ms/step - loss: 0.1777 - accuracy: 0.9451 - val_loss: 0.2818 - val_accuracy: 0.8880
Epoch 5/20
30/30 [==============================] - 0s 13ms/step - loss: 0.1419 - accuracy: 0.9561 - val_loss: 0.2808 - val_accuracy: 0.8868
Epoch 6/20
30/30 [==============================] - 0s 13ms/step - loss: 0.1189 - accuracy: 0.9645 - val_loss: 0.2959 - val_accuracy: 0.8857
Epoch 7/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0949 - accuracy: 0.9735 - val_loss: 0.3122 - val_accuracy: 0.8812
Epoch 8/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0790 - accuracy: 0.9782 - val_loss: 0.4285 - val_accuracy: 0.8579
Epoch 9/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0689 - accuracy: 0.9810 - val_loss: 0.3521 - val_accuracy: 0.8793
Epoch 10/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0525 - accuracy: 0.9881 - val_loss: 0.3976 - val_accuracy: 0.8747
Epoch 11/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0451 - accuracy: 0.9897 - val_loss: 0.4112 - val_accuracy: 0.8725
Epoch 12/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0344 - accuracy: 0.9934 - val_loss: 0.4426 - val_accuracy: 0.8699
Epoch 13/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0284 - accuracy: 0.9940 - val_loss: 0.4725 - val_accuracy: 0.8716
Epoch 14/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0224 - accuracy: 0.9965 - val_loss: 0.5169 - val_accuracy: 0.8676
Epoch 15/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0175 - accuracy: 0.9972 - val_loss: 0.5244 - val_accuracy: 0.8726
Epoch 16/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0126 - accuracy: 0.9986 - val_loss: 0.5545 - val_accuracy: 0.8710
Epoch 17/20
30/30 [==============================] - 0s 12ms/step - loss: 0.0110 - accuracy: 0.9987 - val_loss: 0.5868 - val_accuracy: 0.8687
Epoch 18/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0104 - accuracy: 0.9981 - val_loss: 0.6241 - val_accuracy: 0.8672
Epoch 19/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0046 - accuracy: 0.9999 - val_loss: 0.6510 - val_accuracy: 0.8658
Epoch 20/20
30/30 [==============================] - 0s 13ms/step - loss: 0.0059 - accuracy: 0.9993 - val_loss: 0.6874 - val_accuracy: 0.8656
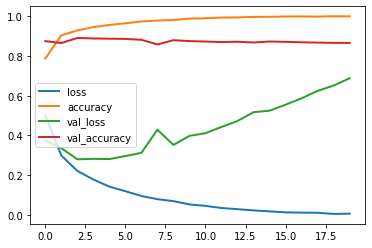
We can now visualize the learning curves
The training loss keeps decreasing, due to gradient descent
The validation loss peaks after a few epochs, after which the model starts to overfit
# Using pandas' built-in plotting of series
pd.DataFrame(history.history).plot(lw=2);
Predictions#
Out of curiosity, let’s look at a few predictions:
predictions = model.predict(x_test)
print("Review 0: ", ' '.join([reverse_word_index.get(i - 3, '?') for i in test_data[0]]))
print("Predicted positiveness: ", predictions[0])
print("\nReview 16: ", ' '.join([reverse_word_index.get(i - 3, '?') for i in test_data[16]]))
print("Predicted positiveness: ", predictions[16])
2022-02-02 16:25:53.294314: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
Review 0: ? please give this one a miss br br ? ? and the rest of the cast rendered terrible performances the show is flat flat flat br br i don't know how michael madison could have allowed this one on his plate he almost seemed to know this wasn't going to work out and his performance was quite ? so all you madison fans give this a miss
Predicted positiveness: [0.00635761]
Review 16: ? from 1996 first i watched this movie i feel never reach the end of my satisfaction i feel that i want to watch more and more until now my god i don't believe it was ten years ago and i can believe that i almost remember every word of the dialogues i love this movie and i love this novel absolutely perfection i love willem ? he has a strange voice to spell the words black night and i always say it for many times never being bored i love the music of it's so much made me come into another world deep in my heart anyone can feel what i feel and anyone could make the movie like this i don't believe so thanks thanks
Predicted positiveness: [0.80061406]
Multi-class classification (topic classification)#
Dataset: 11,000 news stories, 46 topics
Included in Keras, with a 50/50 train-test split
Each row is one news story, with only the 10,000 most frequent words retained
Again, each word is replaced by a word index (word ID)
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# Note that our indices were offset by 3
# because 0, 1 and 2 are reserved indices for "padding", "start of sequence", and "unknown".
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print("News wire: ",decoded_newswire)
print("Encoded: ", train_data[0][0:20])
print("Topic: ",train_labels[0])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/reuters.npz
2113536/2110848 [==============================] - 4s 2us/step
2121728/2110848 [==============================] - 4s 2us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/reuters_word_index.json
557056/550378 [==============================] - 0s 0us/step
565248/550378 [==============================] - 0s 0us/step
News wire: ? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
Encoded: [1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7]
Topic: 3
Preparing the data#
As in the previous example, we need to vectorize the data (e.g. using one-hot-encoding)
Since we now have 46 classes, we need to vectorize the labels as well
We can use one-hot-encoding with Keras’
to_categoricalutilityThis yields a vector of 46 floats (0/1) for every sample
from tensorflow.keras.utils import to_categorical
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
Building the model#
This time we use 64 hidden units because we have many more classes to learn.
In the final layer we can still use the softmax activation function.
The loss function is now
categorical_crossentropy
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
Training and tuning#
We again take a validation set from the training set
We fit the model with 20 epochs
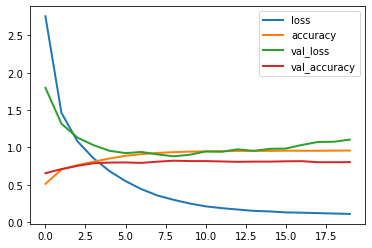
Plot the learning curves
x_val, partial_x_train = x_train[:1000], x_train[1000:]
y_val, partial_y_train = one_hot_train_labels[:1000], one_hot_train_labels[1000:]
history2 = model.fit(partial_x_train,
partial_y_train,
epochs=20, verbose=1,
batch_size=512,
validation_data=(x_val, y_val))
Epoch 1/20
2022-02-02 16:26:00.291793: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
16/16 [==============================] - 1s 17ms/step - loss: 2.7551 - accuracy: 0.5128 - val_loss: 1.7982 - val_accuracy: 0.6560
Epoch 2/20
13/16 [=======================>......] - ETA: 0s - loss: 1.5043 - accuracy: 0.6980
2022-02-02 16:26:01.201983: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
16/16 [==============================] - 0s 12ms/step - loss: 1.4631 - accuracy: 0.7048 - val_loss: 1.3179 - val_accuracy: 0.7110
Epoch 3/20
16/16 [==============================] - 0s 11ms/step - loss: 1.0819 - accuracy: 0.7645 - val_loss: 1.1319 - val_accuracy: 0.7540
Epoch 4/20
16/16 [==============================] - 0s 11ms/step - loss: 0.8560 - accuracy: 0.8092 - val_loss: 1.0311 - val_accuracy: 0.7890
Epoch 5/20
16/16 [==============================] - 0s 11ms/step - loss: 0.6840 - accuracy: 0.8530 - val_loss: 0.9559 - val_accuracy: 0.7980
Epoch 6/20
16/16 [==============================] - 0s 11ms/step - loss: 0.5503 - accuracy: 0.8887 - val_loss: 0.9247 - val_accuracy: 0.8000
Epoch 7/20
16/16 [==============================] - 0s 11ms/step - loss: 0.4419 - accuracy: 0.9107 - val_loss: 0.9400 - val_accuracy: 0.7940
Epoch 8/20
16/16 [==============================] - 0s 11ms/step - loss: 0.3577 - accuracy: 0.9275 - val_loss: 0.9076 - val_accuracy: 0.8100
Epoch 9/20
16/16 [==============================] - 0s 11ms/step - loss: 0.3002 - accuracy: 0.9374 - val_loss: 0.8816 - val_accuracy: 0.8230
Epoch 10/20
16/16 [==============================] - 0s 11ms/step - loss: 0.2513 - accuracy: 0.9445 - val_loss: 0.9024 - val_accuracy: 0.8180
Epoch 11/20
16/16 [==============================] - 0s 14ms/step - loss: 0.2127 - accuracy: 0.9481 - val_loss: 0.9468 - val_accuracy: 0.8180
Epoch 12/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1888 - accuracy: 0.9501 - val_loss: 0.9425 - val_accuracy: 0.8130
Epoch 13/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1700 - accuracy: 0.9543 - val_loss: 0.9748 - val_accuracy: 0.8080
Epoch 14/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1521 - accuracy: 0.9540 - val_loss: 0.9547 - val_accuracy: 0.8110
Epoch 15/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1447 - accuracy: 0.9540 - val_loss: 0.9819 - val_accuracy: 0.8110
Epoch 16/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1320 - accuracy: 0.9574 - val_loss: 0.9855 - val_accuracy: 0.8150
Epoch 17/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1278 - accuracy: 0.9560 - val_loss: 1.0335 - val_accuracy: 0.8170
Epoch 18/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1223 - accuracy: 0.9560 - val_loss: 1.0732 - val_accuracy: 0.8030
Epoch 19/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1167 - accuracy: 0.9575 - val_loss: 1.0764 - val_accuracy: 0.8030
Epoch 20/20
16/16 [==============================] - 0s 11ms/step - loss: 0.1115 - accuracy: 0.9592 - val_loss: 1.1050 - val_accuracy: 0.8040
pd.DataFrame(history2.history).plot(lw=2);
model.fit(partial_x_train, partial_y_train, epochs=8, batch_size=512, verbose=0)
result = model.evaluate(x_test, one_hot_test_labels)
print("Loss: {:.4f}, Accuracy: {:.4f}".format(*result))
71/71 [==============================] - 1s 8ms/step - loss: 1.3110 - accuracy: 0.7832
Loss: 1.3110, Accuracy: 0.7832
Regression#
Dataset: 506 examples of houses and sale prices (Boston)
Included in Keras, with a 1/5 train-test split
Each row is one house price, described by numeric properties of the house and neighborhood
Small dataset, non-normalized features
from tensorflow.keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/boston_housing.npz
57344/57026 [==============================] - 0s 7us/step
65536/57026 [==================================] - 0s 6us/step
Building the network#
This is a small dataset, so easy to overfit
We use 2 hidden layers of 64 units each
Use smaller batches, more epochs
Since we want scalar output, the output layer is one unit without activation
Loss function is Mean Squared Error (bigger penalty)
Evaluation metric is Mean Absolute Error (more interpretable)
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
Preprocessing#
Neural nets work a lot better if we standardize the features first.
Keras has no built-in support so we have to do this ourselves
We can use scikit-learn preprocessors and build a pipeline with KerasClassifier
Or, more futureproof, we can use TFX
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from keras.wrappers.scikit_learn import KerasRegressor, KerasClassifier
estimators = []
estimators.append(('standardise', StandardScaler()))
estimators.append(('keras', KerasRegressor(build_fn=build_model)))
pipeline = Pipeline(estimators)
/var/folders/0t/5d8ttqzd773fy0wq3h5db0xr0000gn/T/ipykernel_63784/292072420.py:7: DeprecationWarning: KerasRegressor is deprecated, use Sci-Keras (https://github.com/adriangb/scikeras) instead.
estimators.append(('keras', KerasRegressor(build_fn=build_model)))
Evaluate the Keras pipeline with cross-validation
from sklearn.model_selection import cross_validate
clf = KerasClassifier(build_model)
X = np.concatenate([train_data,test_data],axis=0)
y = np.concatenate([train_targets,test_targets],axis=0)
scores = cross_validate(pipeline, X, y, cv=3,
scoring=('neg_mean_squared_error'),
return_train_score=True,
fit_params={'keras__epochs': 50, 'keras__batch_size':1, 'keras__verbose':0})
/var/folders/0t/5d8ttqzd773fy0wq3h5db0xr0000gn/T/ipykernel_63784/146990890.py:2: DeprecationWarning: KerasClassifier is deprecated, use Sci-Keras (https://github.com/adriangb/scikeras) instead.
clf = KerasClassifier(build_model)
2022-02-02 16:30:58.090909: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
2022-02-02 16:31:48.676628: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
2022-02-02 16:31:48.988794: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
2022-02-02 16:32:38.757530: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
2022-02-02 16:32:38.929908: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
2022-02-02 16:33:29.757842: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
print("MAE: ", -np.mean(scores['test_score']))
MAE: 14.731411012765486
Regularization#
Adding L1/L2 regularization
The input (0.001) is the alpha value
from tensorflow.keras import regularizers
l2_model = models.Sequential()
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
l2_model.add(layers.Dense(1, activation='sigmoid'))
l2_model.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_15 (Dense) (None, 16) 160016
dense_16 (Dense) (None, 16) 272
dense_17 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Adding dropout
The input (0.5) is the dropout rate
dpt_model = models.Sequential()
dpt_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(16, activation='relu'))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(1, activation='sigmoid'))
dpt_model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_18 (Dense) (None, 16) 160016
dropout (Dropout) (None, 16) 0
dense_19 (Dense) (None, 16) 272
dropout_1 (Dropout) (None, 16) 0
dense_20 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________
Word embeddings in Keras#
Uses a pre-trained embedding, obtained using GloVe
See a complete example here
from tensorflow.keras.layers import Embedding, Flatten, Dense
max_length = 20 # pad documents to a maximum number of words
vocab_size = 10000 # vocabulary size
embedding_length = 300 # vocabulary size
# define the model
model = models.Sequential()
model.add(Embedding(vocab_size, embedding_length, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# summarize the model
print(model.summary())
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 20, 300) 3000000
flatten (Flatten) (None, 6000) 0
dense_21 (Dense) (None, 1) 6001
=================================================================
Total params: 3,006,001
Trainable params: 3,006,001
Non-trainable params: 0
_________________________________________________________________
None
Further reading#
https://www.tensorflow.org/learn