Anna Vettoruzzo
Overview¶
Transformer model (recap)
Pre-training vs. post-training
Supervised fine-tuning
Parameter-efficient fine-tuning
LoRA: Low Rank Adaptation
Advanced insights into LoRA
Transformer model (recap)¶
| Source: https://machinelearningmastery.com/encoders-and-decoders-in-transformer-models/ |
But ... there are different variations of this architecture
Encoder-decoder models (e.g., T5) are ideal for seq-to-seq tasks like translation.
Decoder-only models (e.g., GPT) generate text (next-token prediction). They rely on masked (causal) self-attention where a token at position i only attends to tokens at position i-1.
Encoder-only models (e.g., BERT) extract sentence embeddings. To do so they use bi-directional self-attention (i.e., the representation of a token at position i is informed by tokens at position i-1 and i+1).
In this lecture, we will focus on a decoder-only architecture!
Large Language Models (LLMs)¶
Large decoder-only models with hundreds of billions of parameters. The larger the model, the better the performance.
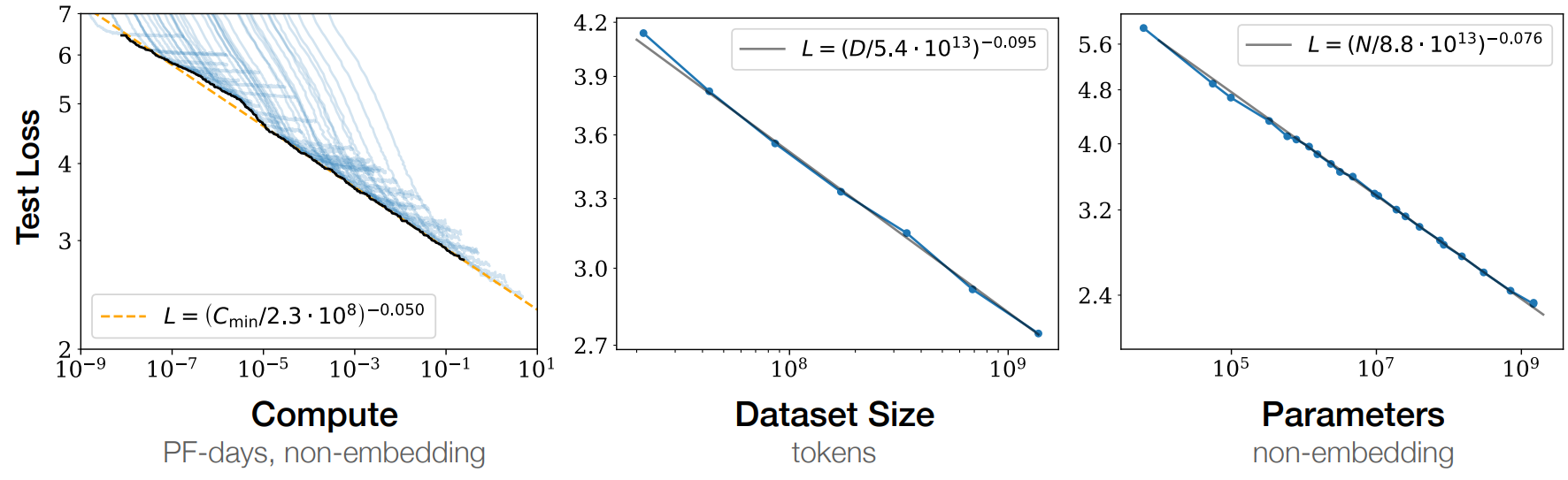
Source: Scaling Laws for Neural Language Models (Kaplan et al.)
Increase the model size → Increase in the number of GPUs/time needed for training → Increase in cost. 🤑
Training a model from scratch for each task is not feasible. The solution is to divide the training pipeline into two different phases: pre-training and post-training.
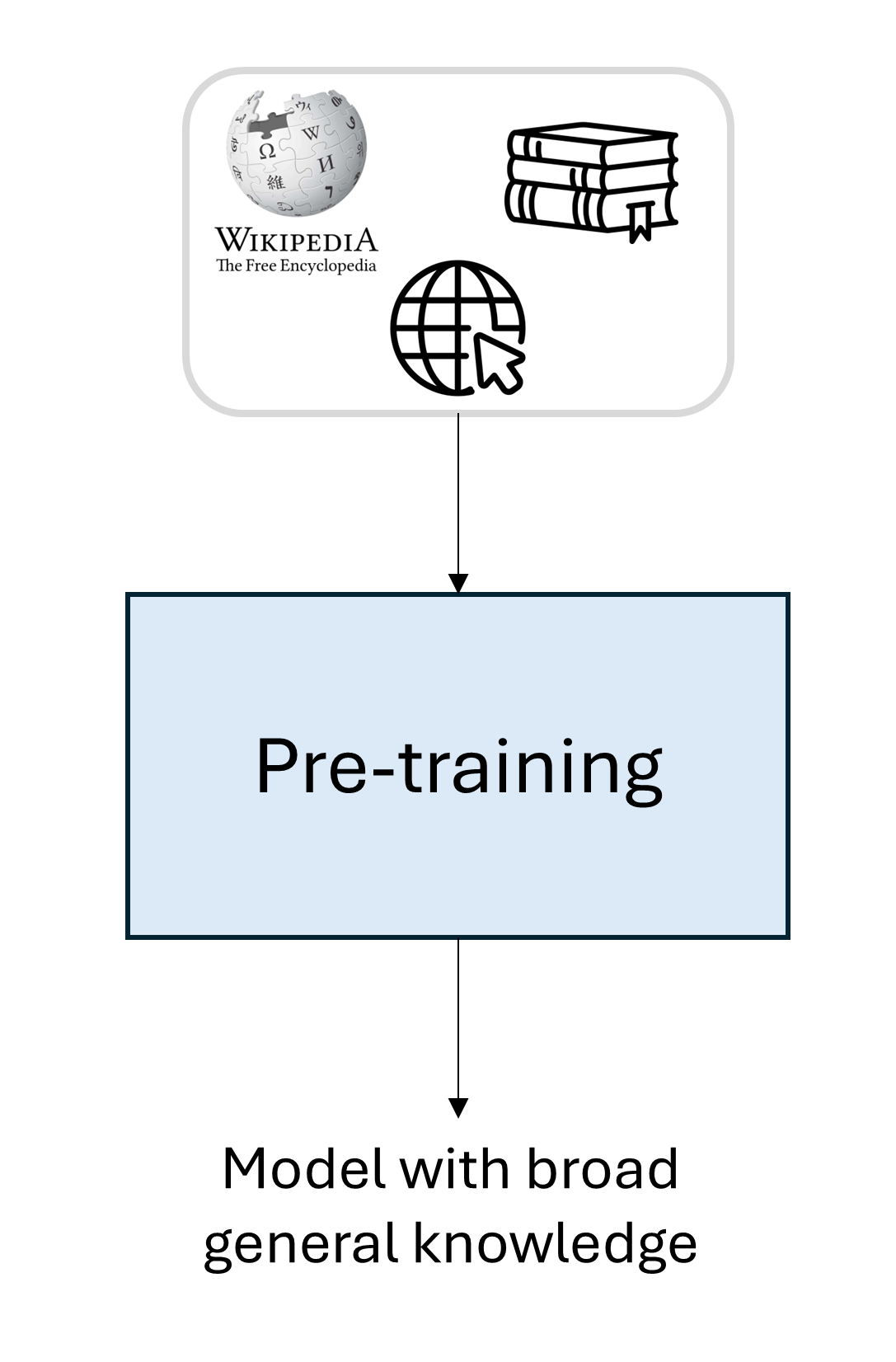
Pre-training¶
Goal: Learn language & world knowledge.
Input: Massive raw datasets.
Outcome: A base model.
Limit: Only predicts the next token; doesn't "follow instructions."
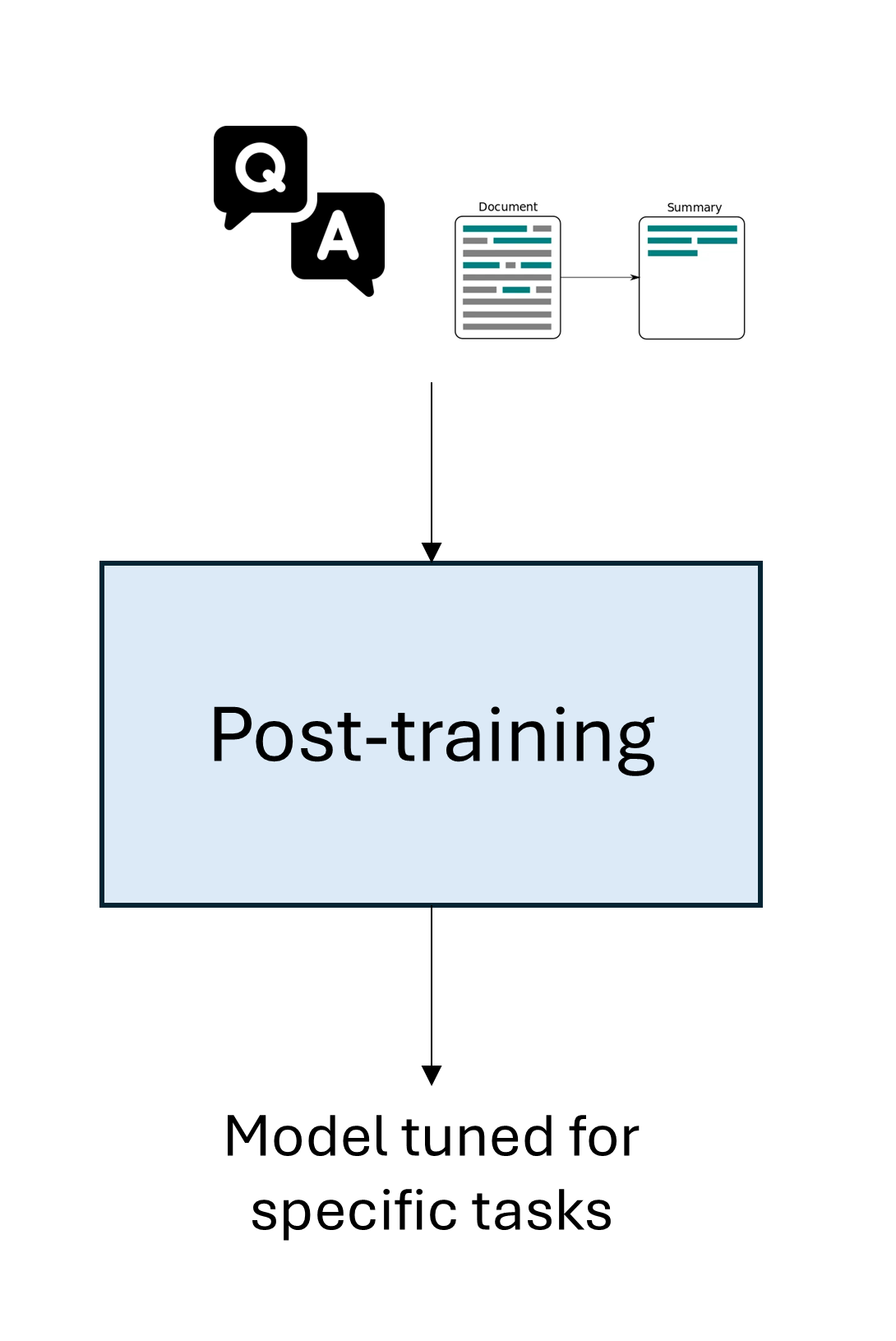
Post-training¶
Goal: Refining a pre-trained model to behave in a specific, useful, and safe way.
Methods:
Supervised fine-tuning (SFT): Adapts model to specific tasks or domains. Outcome: an instruction-tuned model.
Preference tuning: Ensures responses are in the correct format, helpful & harmless. Methods: RLHF, DPO.
So, you can see that there is a paradigm shift from tradition ML and LLM training:
Traditional ML. We train a model for each task, or we apply transfer learning by reusing the trained model to some capacity.
LLM training. The idea is to train the model to understand general knowledge, then tune it for an end task.
An example with a simple prompt (remember that the generation is randomic!)

Authenticate and load the model
# Authentication to Hugging Face
hf_token = ... # TODO: add your HF token here
login(hf_token)
# Model configuration
# Feel free to try with a different model
base_model_name = "meta-llama/Llama-3.2-1B"
# Load models and tokenizers
base_tokenizer = AutoTokenizer.from_pretrained(base_model_name, use_fast=True)
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
dtype=torch.float16
)Model generation
# Simple prompt
simple_prompt = "What is the capital of the Netherlands?"
# Tokenize prompt using base tokenizer
inputs = base_tokenizer(simple_prompt, return_tensors="pt").to(device)
print(f"\nPrompt = {simple_prompt}\n")
# Generate output
with torch.no_grad():
outputs_base = base_model.generate(**inputs, max_new_tokens=150)
print("Base model:\n", base_tokenizer.decode(outputs_base[0], skip_special_tokens=True))Generation with an instruction-tuned model
# Better to run the code on Colab where a GPU is available for free
# Model configuration
# Feel free to try with a different model
inst_model_name = "meta-llama/Llama-3.2-1B-Instruct"
# Load model and tokenizer
inst_tokenizer = AutoTokenizer.from_pretrained(inst_model_name, use_fast=True)
inst_model = AutoModelForCausalLM.from_pretrained(
inst_model_name,
device_map="auto",
dtype=torch.float16
)
# Simple prompt
inputs = inst_tokenizer(simple_prompt, return_tensors="pt").to(device)
# Generate output
with torch.no_grad():
outputs_it = inst_model.generate(**inputs, max_new_tokens=150)
print("\nInstruction-tuned model:\n", inst_tokenizer.decode(outputs_it[0], skip_special_tokens=True))# Model generation (complete code)
# Better to run the code in Google Colab where a GPU is available for free
import torch
from huggingface_hub import login
from transformers import AutoModelForCausalLM, AutoTokenizer
# Authentication to Hugging Face
hf_token = ... # TODO: add your HF token here
login(hf_token)
# Use CUDA if available
device = "cuda" if torch.cuda.is_available() else "cpu"
# Model configuration
# Feel free to try with a different model
base_model_name = "meta-llama/Llama-3.2-1B"
# Load models and tokenizers
base_tokenizer = AutoTokenizer.from_pretrained(base_model_name, use_fast=True)
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
dtype=torch.float16
)
# Simple prompt
simple_prompt = "What is the capital of the Netherlands?"
# Tokenize prompt using base tokenizer
inputs = base_tokenizer(simple_prompt, return_tensors="pt").to(device)
print(f"\nPrompt = {simple_prompt}\n")
# Generate output
with torch.no_grad():
outputs_base = base_model.generate(**inputs, max_new_tokens=150)
print("Base model:\n", base_tokenizer.decode(outputs_base[0], skip_special_tokens=True))
# Generation with a instruction-tuned model
# Better to run the code on Colab where a GPU is available for free
# Model configuration
# Feel free to try with a different model
inst_model_name = "meta-llama/Llama-3.2-1B-Instruct"
# Load model and tokenizer
inst_tokenizer = AutoTokenizer.from_pretrained(inst_model_name, use_fast=True)
inst_model = AutoModelForCausalLM.from_pretrained(
inst_model_name,
device_map="auto",
dtype=torch.float16
)
# Simple prompt
inputs = inst_tokenizer(simple_prompt, return_tensors="pt").to(device)
# Generate output
with torch.no_grad():
outputs_it = inst_model.generate(**inputs, max_new_tokens=150)
print("\nInstruction-tuned model:\n", inst_tokenizer.decode(outputs_it[0], skip_special_tokens=True))Supervised Fine-Tuning (SFT)¶
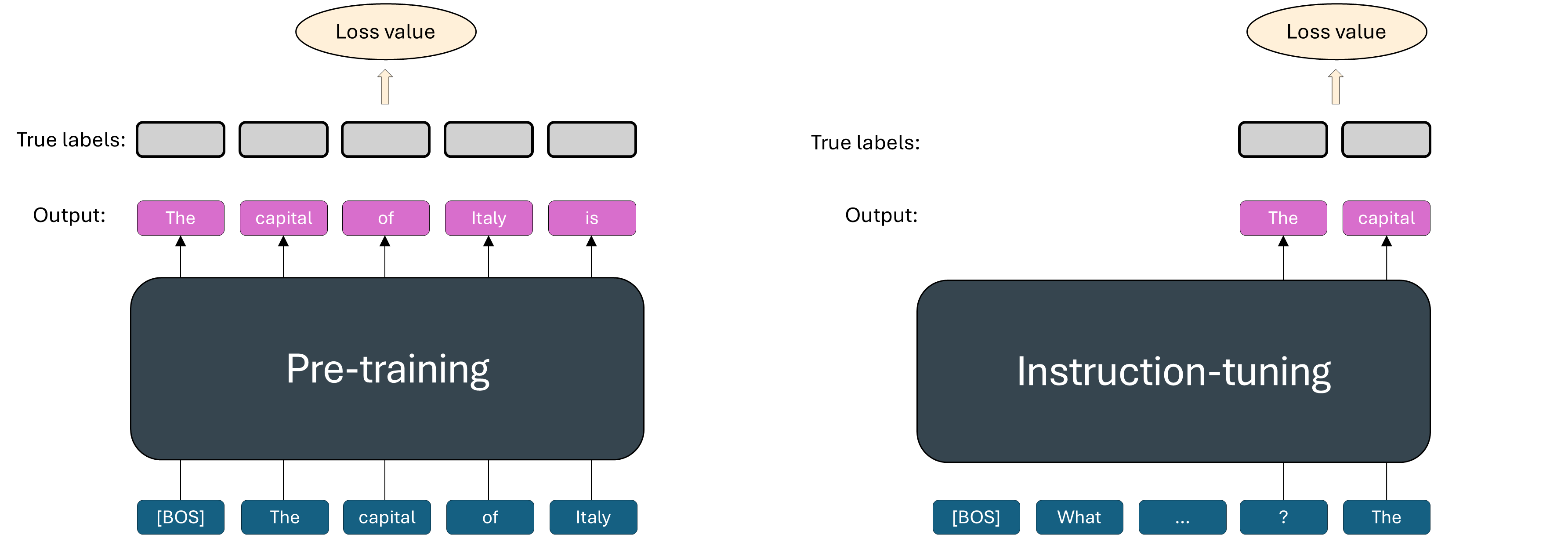
SFT, or instruction-tuning, adapts pre-trained models using labeled task-specific input/output pairs to improve performance and instruction-following capabilities.
Strategy:
Collect pairs of input/outputs with desired behavior.
The objective function is the same as the pre-trained task (next-token prediction) but the model is given the whole input and it tries to predict the output. The loss calculation is only on the output prediction.
The standard SFT approach is also called Full Fine-Tuning (FullFT) where all model weights are updated during the process.
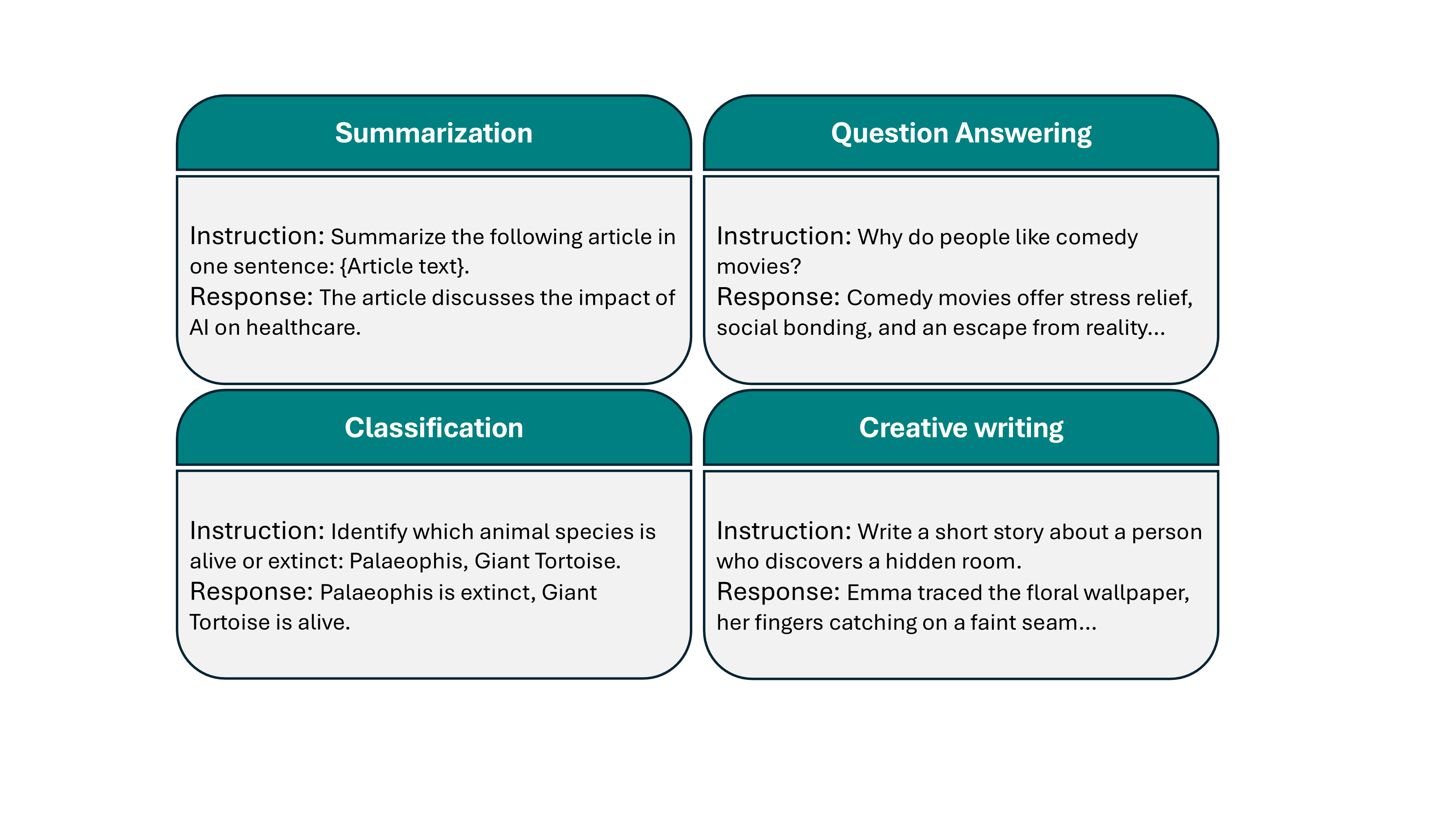
Data for instruction-tuning¶
High quality data
Can be both human written or synthetic data
It usually consists of millions or few billions of tokens vs. trillion of tokens for pre-training
Challenges of FullFT¶
Very high quality data needed as it directly determines the model’s capability for the task
Risk of overfitting on small datasets
Need to store full model checkpoints for each fine-tuned model
Risk of catastrophic forgetting of the pre-trained knowledge
Computationally expensive
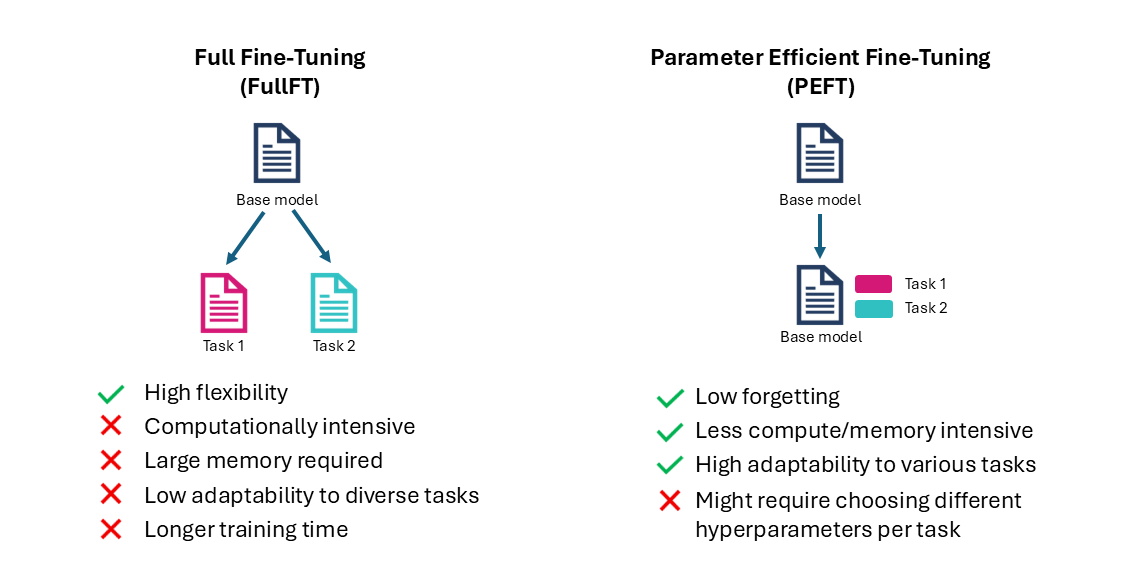
PEFT¶
FullFT involves updating every single weight of the model.
Parameter Efficient Fine-Tuning (PEFT) updates only a small set of parameters, while the others remain frozen.
Example
Fine-tuning a 7B parameter model using FullFT can require up to 50GB of GPU VRAM and only 20GB using PEFT techniques (actual memory usage depends on batch size, sequence length, and specific model architecture).
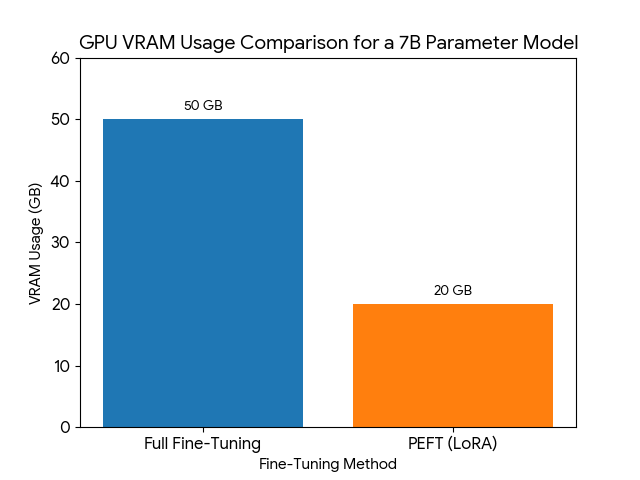
Image generated with Nano Banana.
PEFT methods¶
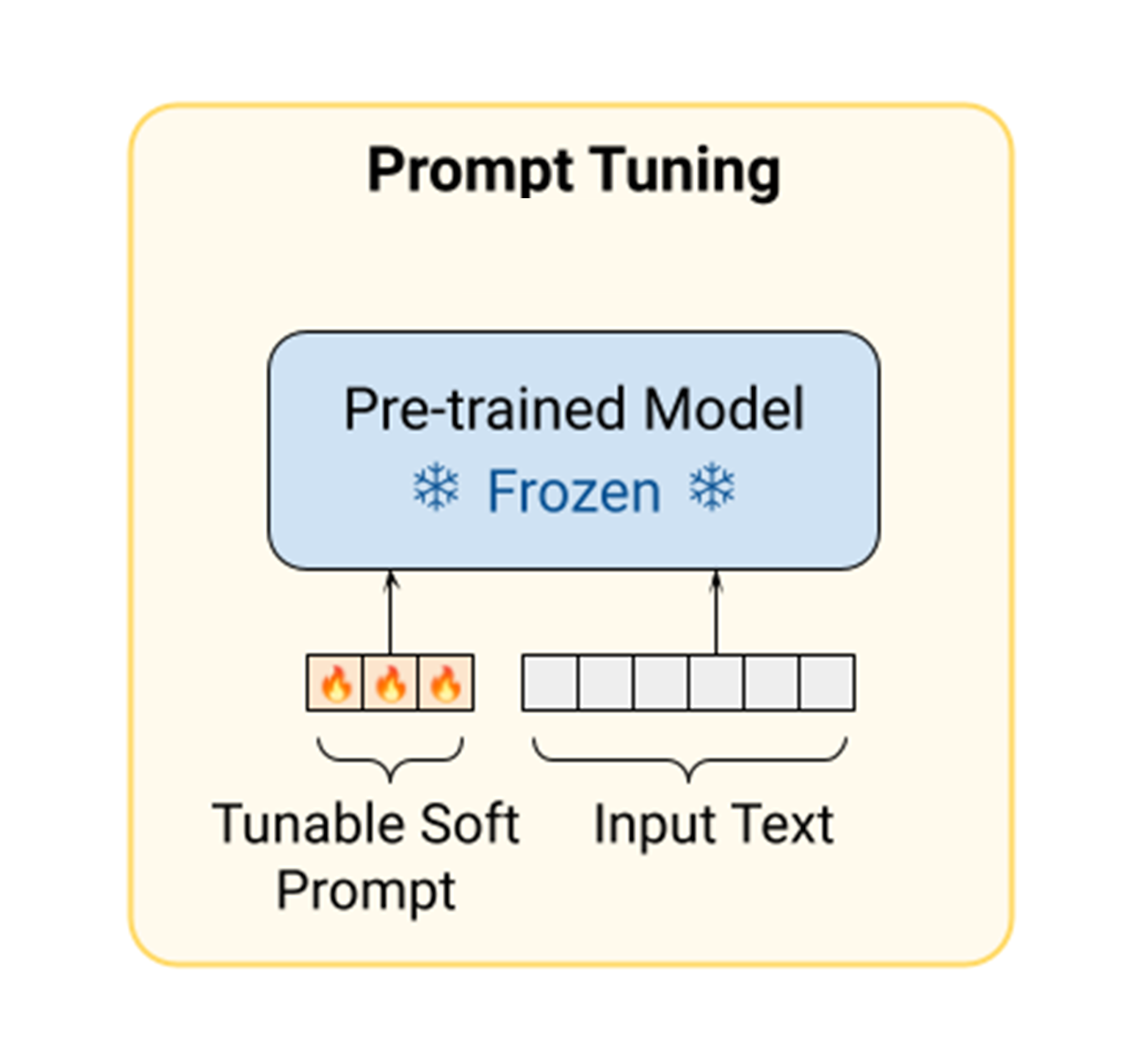
Prompt tuning¶
Learning "soft prompts" through backpropagation to condition frozen language models to perform specific downstream tasks.
Adapter layers¶
Adapters are new per-task modules added between layers of a pre-trained network.
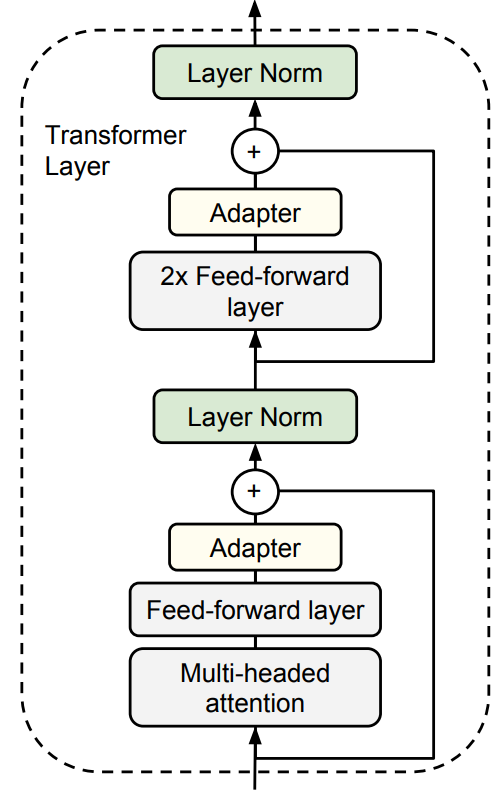
LoRA¶
Approximate the weight updates with small tunable matrices.
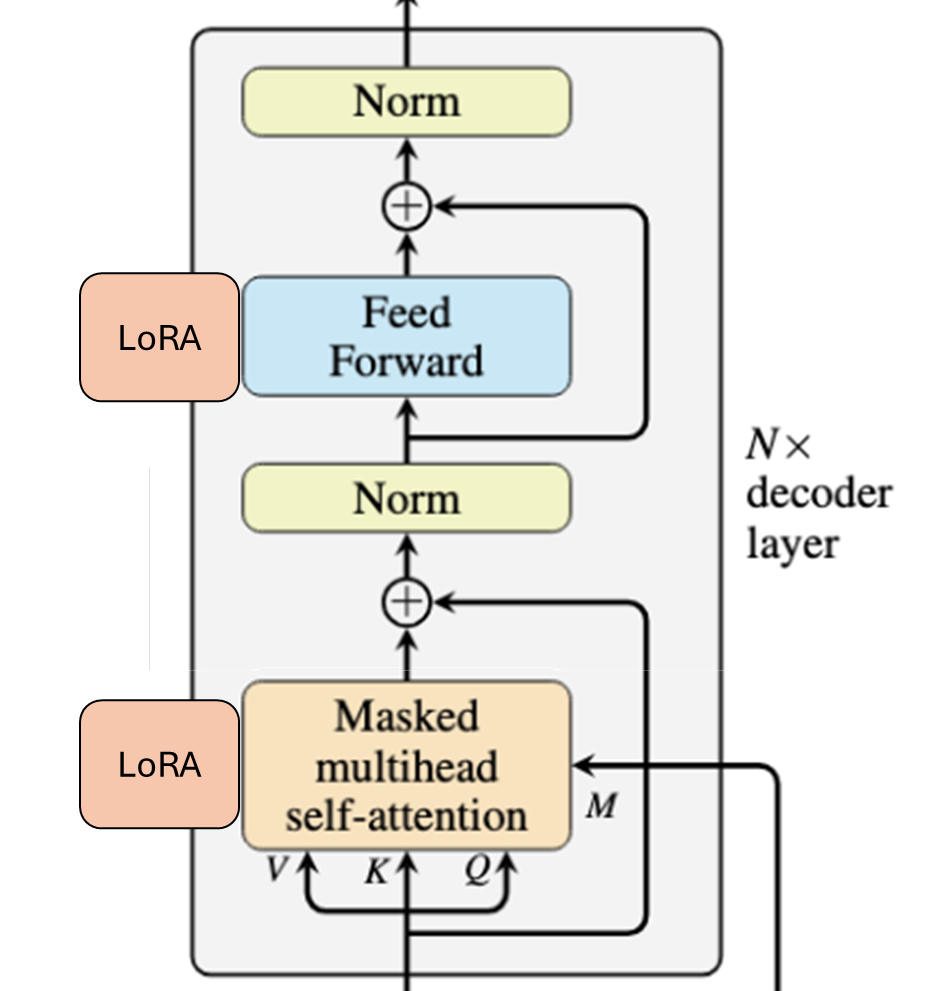
Low Rank Adaptation (LoRA)¶
| 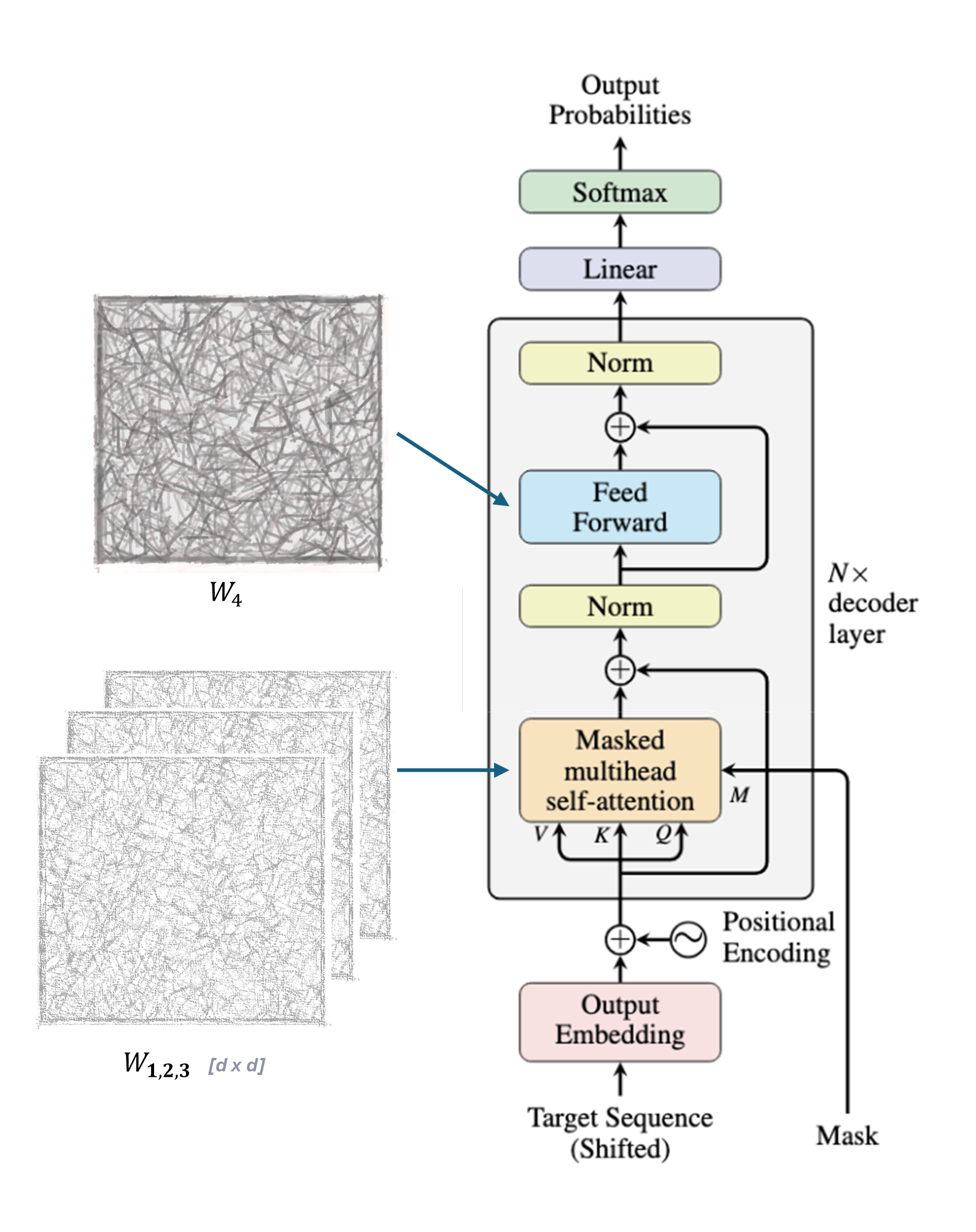 |
Instead of learning the update for each weight during backpropagation, we can approximate it using a technique called low-rank approximation:
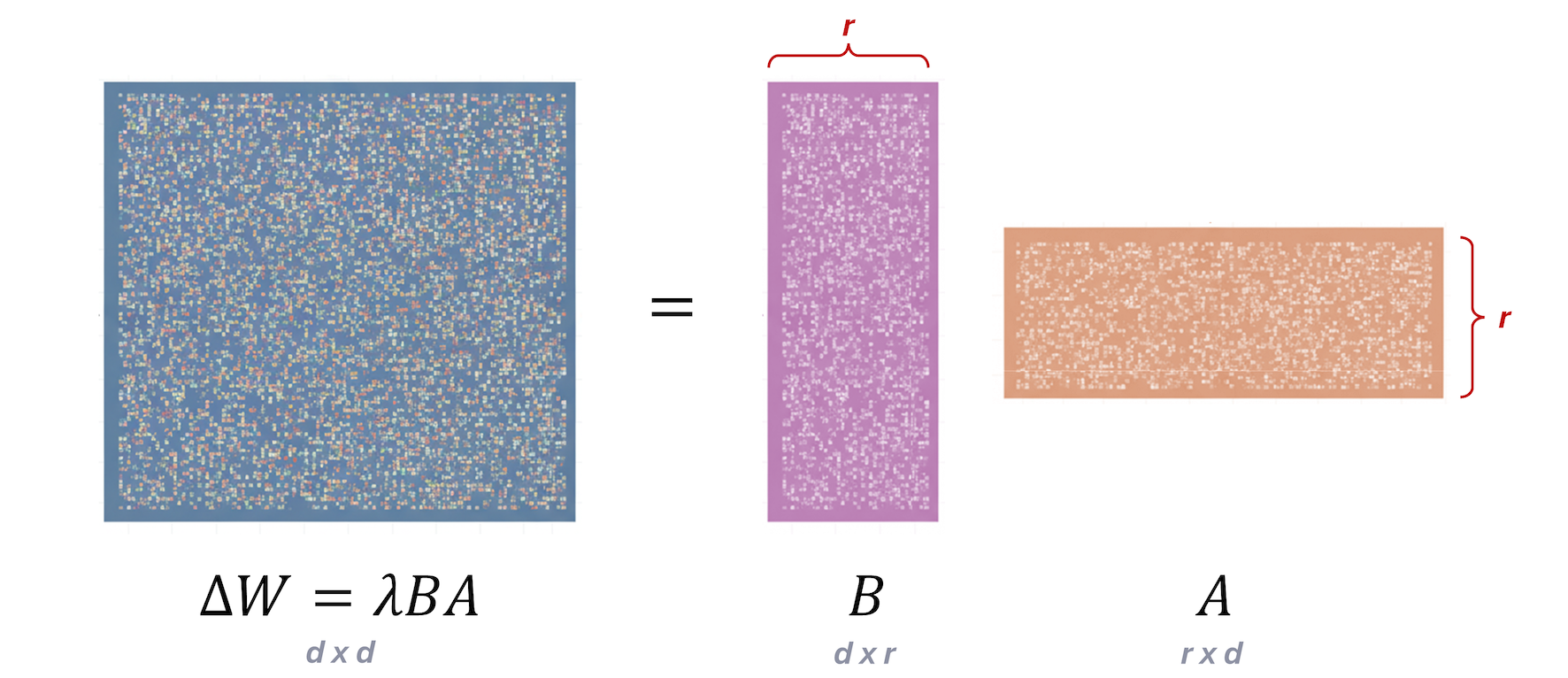
Therefore, the fine-tuned weight matrix can be expressed as .
You might wonder how small the A and B matrices are, and this depends on the rank r which will see in a few slides.
Note: and are usually initialized as and .
Gradient descent with LoRA¶
Mini-batch Stochastic Gradient Descent (recap)
Draw a batch of batch_size training data and
Forward pass : pass though the network to yield predictions
Compute the loss (mismatch between and )
Backward pass : Compute the gradient of the loss with regard to every weight
Backpropagate the gradients through all the layers
Update :
Repeat until n passes (epochs) are made through the entire training set.
With LoRA
| 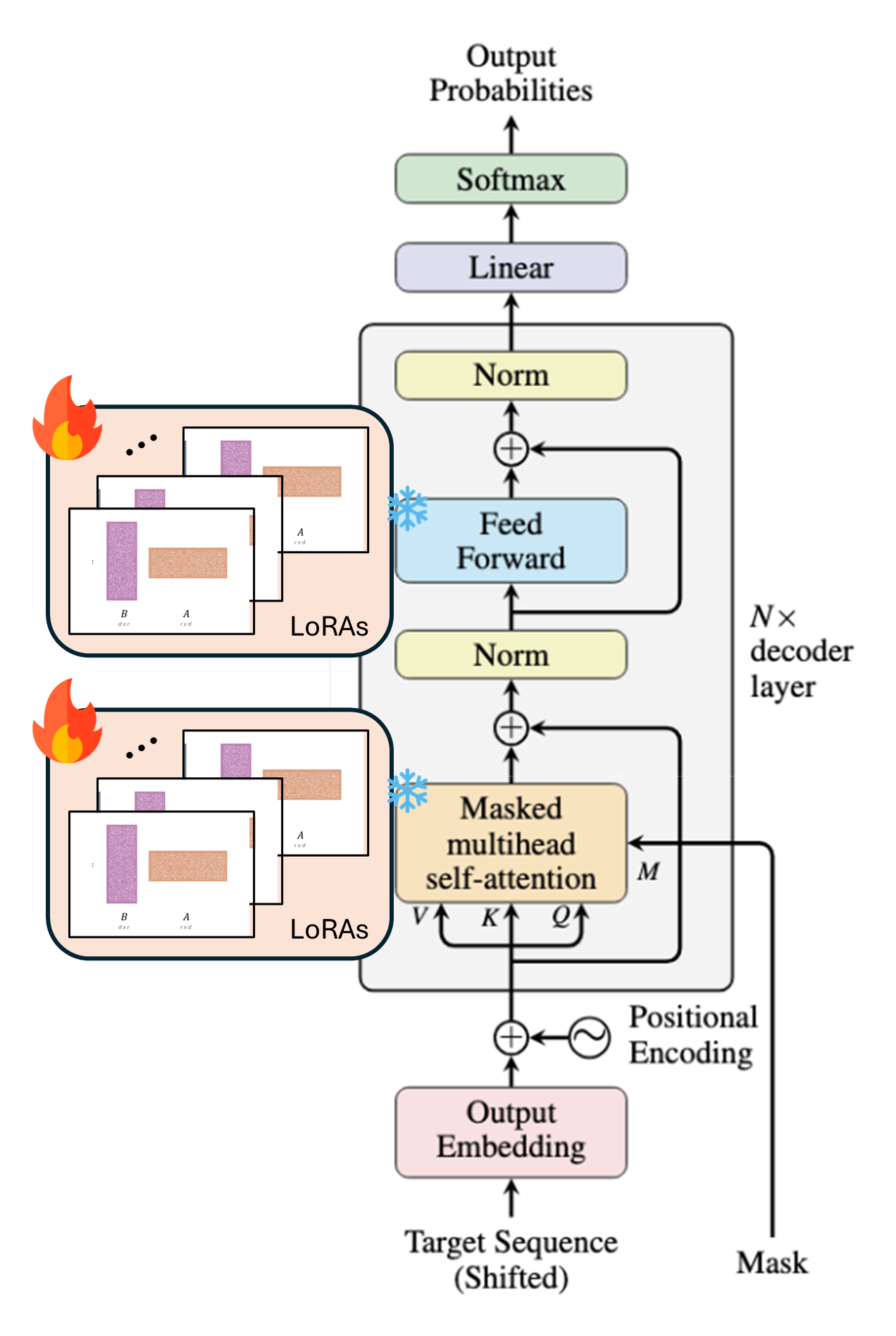 |
Benefits of LoRA¶
| 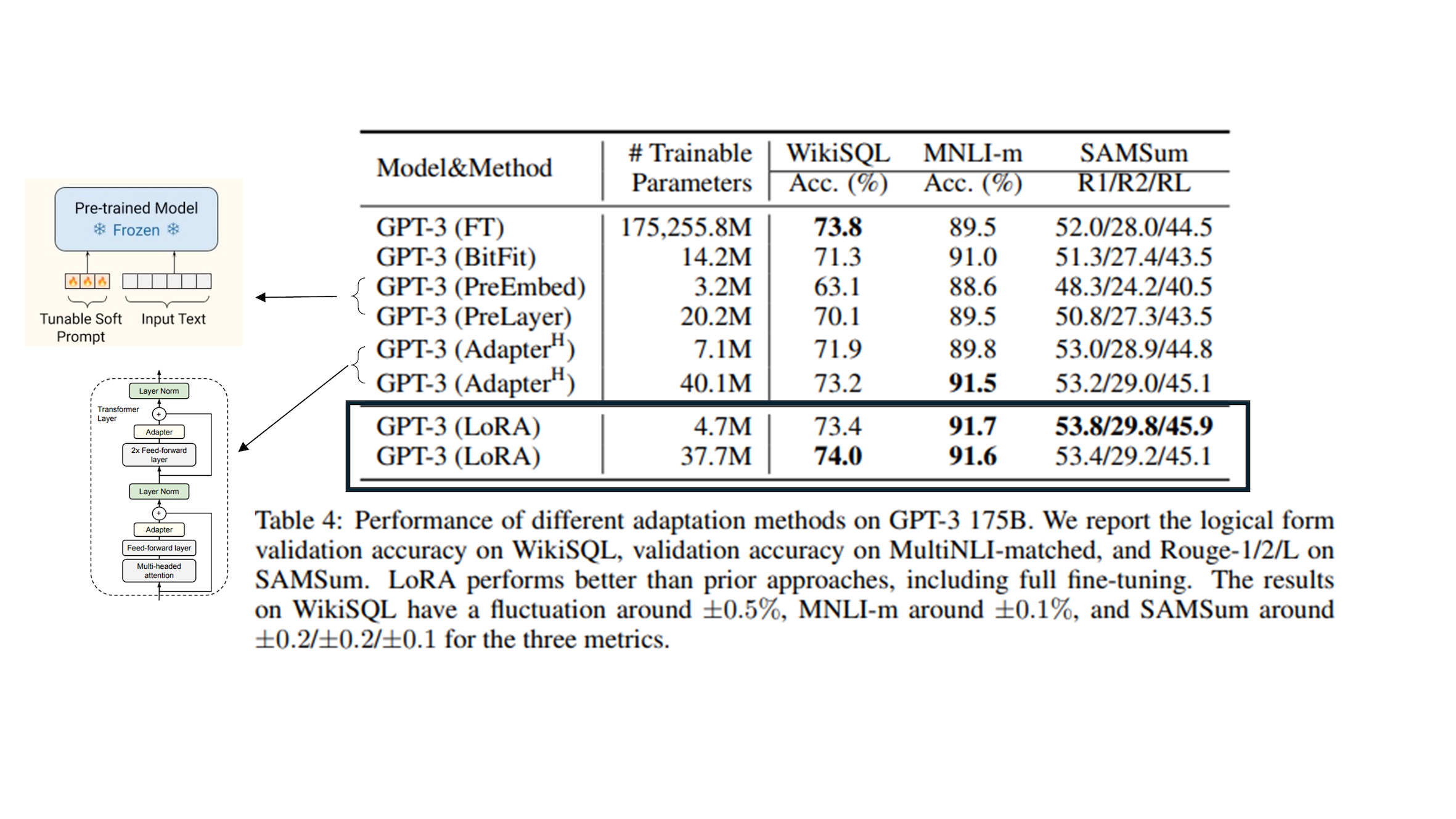 Source: LoRA: Low-Rank Adaptation of Large Language Models (Hu et al.) |
Exercise 1¶
How much memory does this save?
Assume an LLM has
with 10,000 rows and 10,000 columns → total of 100,000,000 parameters.
If we choose A and B with r=8,
A has 10,000 rows and 8 columns, B has 8 rows and 10,000 columns → total 10,000×8 + 8×10,000 = 160,000
625× less than 100,000,000!!
Exercise 2¶
How to calculate the number of trainable parameters in LoRA?
where is the number of weight matrices we apply LoRA to.
Let’s take a look at how to use LoRA in Python code.
Dataset loading
# Better to run the code in Colab where a GPU is available for free
# Load the dataset
dataset = "fka/awesome-chatgpt-prompts"
data = load_dataset(dataset)
data = data.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample = data["train"].select(range(50))
train_sample = train_sample.remove_columns('act')
display(train_sample)

Model loading and LoRA configuration
# Load the model and the tokenizer
model_name = "bigscience/bloomz-560m" # feel free to try with other models. You can find the list of supported models here: https://huggingface.co/docs/peft/main/en/index#supported-methods
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Import Lora fine-tuning configuration
lora_config = LoraConfig(
r=4, # rank controls the number of trainable parameters
lora_alpha=4, # a scaling factor that adjusts the magnitude of the weight matrix (lambda=a/r). Usually set equal to r
target_modules=["query_key_value"], # the name of the modules to apply LoRA to. The name depends on the model used
lora_dropout=0.05, # to avoid overfitting
bias="lora_only", # this specifies if the bias parameter should be trained
task_type="CAUSAL_LM"
)
peft_model = get_peft_model(model, lora_config)
print(peft_model.print_trainable_parameters())Train LoRA
# Train the model
output_directory = "./peft_lab_outputs"
training_args = TrainingArguments(
output_dir=output_directory,
auto_find_batch_size=True, # find a batch size that fits the size of the data.
learning_rate= 3e-2,
num_train_epochs=2,
report_to="none"
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_sample,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False) # this is the dataset ready to be processed in blocks
)
trainer.train()Save and load models
# Save the model
output_directory = "./peft_lab_outputs"
peft_model_path = os.path.join(output_directory, f"lora_model")
trainer.model.save_pretrained(peft_model_path)
# Load the model
loaded_model = PeftModel.from_pretrained(model,
peft_model_path,
is_trainable=False).to("cuda")
Model inference
# Inference
# this function returns the outputs from the model based on the given inputs
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=True, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id
)
return outputs
input_sentences = tokenizer("I want you to act as a football coach. ", return_tensors="pt")
foundational_outputs_sentence = get_outputs(loaded_model, input_sentences.to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))
# Fine-tuning with LoRA (complete code)
# Better to run the code in Google Colab where a GPU is available for free
!pip install -q peft
!pip install -q datasets
import os
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
import peft
from peft import LoraConfig, get_peft_model, PeftModel
# Load the model and the tokenizer
model_name = "bigscience/bloomz-560m" # feel free to try with other models. You can find the list of supported models here: https://huggingface.co/docs/peft/main/en/index#supported-methods
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Load the dataset
dataset = "fka/awesome-chatgpt-prompts"
data = load_dataset(dataset)
data = data.map(lambda samples: tokenizer(samples["prompt"]), batched=True)
train_sample = data["train"].select(range(50))
train_sample = train_sample.remove_columns('act')
display(train_sample)
print(train_sample[:1])
# Import Lora fine-tuning configuration
lora_config = LoraConfig(
r=4, # rank controls the number of trainable parameters
lora_alpha=4, # a scaling factor that adjusts the magnitude of the weight matrix (lambda=a/r). Usually set equal to r
target_modules=["query_key_value"], # the name of the modules to apply LoRA to. The name depends on the model used
lora_dropout=0.05, # to avoid overfitting
bias="lora_only", # this specifies if the bias parameter should be trained
task_type="CAUSAL_LM"
)
peft_model = get_peft_model(model, lora_config)
print(peft_model.print_trainable_parameters())
# Train the model
output_directory = "./peft_lab_outputs"
training_args = TrainingArguments(
output_dir=output_directory,
auto_find_batch_size=True, # find a batch size that fits the size of the data.
learning_rate= 3e-2,
num_train_epochs=2,
report_to="none"
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_sample,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False) # this is the dataset ready to be processed in blocks
)
trainer.train()
# Save the model
output_directory = "./peft_lab_outputs"
peft_model_path = os.path.join(output_directory, f"lora_model")
trainer.model.save_pretrained(peft_model_path)
# Load the model
loaded_model = PeftModel.from_pretrained(model,
peft_model_path,
is_trainable=False).to("cuda")
# Inference
# this function returns the outputs from the model based on the given inputs
def get_outputs(model, inputs, max_new_tokens=100):
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens,
repetition_penalty=1.5, #Avoid repetition.
early_stopping=True, #The model can stop before reach the max_length
eos_token_id=tokenizer.eos_token_id
)
return outputs
input_sentences = tokenizer("I want you to act as a football coach. ", return_tensors="pt")
foundational_outputs_sentence = get_outputs(loaded_model, input_sentences.to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(foundational_outputs_sentence, skip_special_tokens=True))More insights into LoRA¶
The role of rank (r) and scaling factor ()¶
r controls the number of trainable parameters.
A smaller r leads to fewer parameters and less memory consumed.
A larger r allows to capture more complex task-specific information. Common values are between and based on the task complexity and the size of the pre-trained model.
controls the magnitude of the weight update.
It is defined as , where is a constant in and it helps stabilize the training.
It is usually set to or as tuning it is the same as tuning the learning rate of the optimizer.
Where to apply LoRA¶
LoRA is most effective when applied to the core computational layers of the transformer.
In the original paper LoRA is applied only to the query and value projection matrices within the self-attention layer.
Recent studies demonstrated that applying LoRA to all self-attention matrices and the FFN layers helps.
More recommendations on how to set LoRA’s hyperparameters can be found in the Unsloth’s LoRA Hyperparameter Guide.
Lora Without Regret (Thinking Machines, 2025)¶
LoRA can be on par with FullFT but only when a few key factors are chosen correctly:
Fine-tuning on small-to-medium-sized datasets that do not exceed LoRA’s capacity.
A sufficiently high rank is used to capture the task’s complexity. Learning slows down when the adapter runs out of capacity, which is determined by the rank.
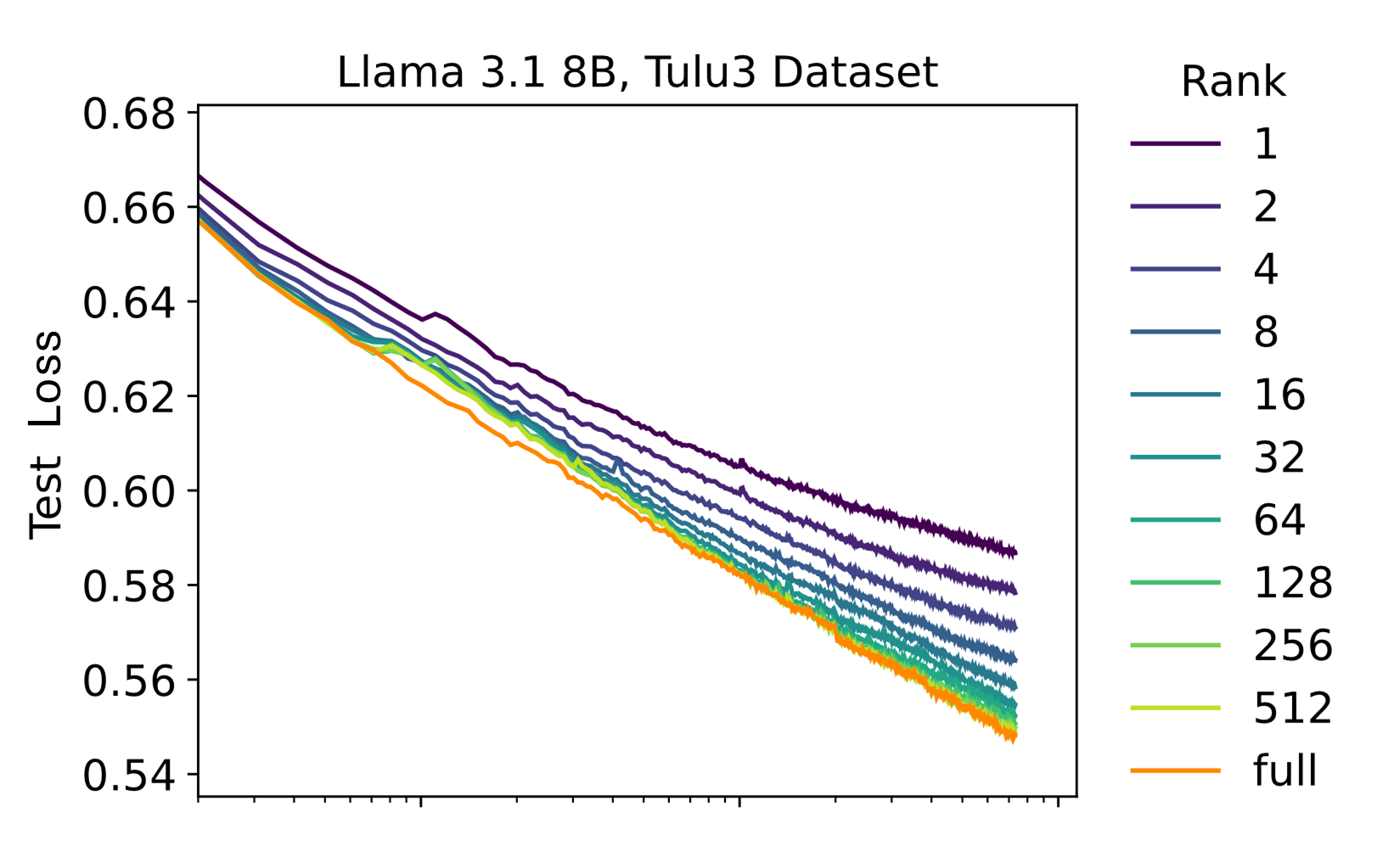
Figure: LoRA training curves for various ranks on Tulu3 and OpenThoughts2 datasets. FullFT and high-rank LoRAs have similar learning curves with loss decreasing linearly with the logarithm of steps. Lower-rank LoRAs dall odd the minimum-loss curve when the adapter runs out of capacity.
Source: Lora Without Regret (Thinking Machines)
The optimal learning rate for LoRA is higher by a factor of 10 than for FullFT.

Figure: Learning rate versus final loss for various LoRA ranks on Tulu3. Minimum loss is approximately the same for high rank LoRA and FullFT. Optimal LR is 10 times higher for LoRA.
Source: Lora Without Regret (Thinking Machines)
LoRA is applied broadly, including the attention matrices and the FFN layers.
LoRA vs Full Fine-tuning: An Illusion of Equivalence (Shuttleworth et al., 2024)¶
The fact that LoRA can match FullFT is only an illusion due to insufficient optimization or testing on limited datasets.
LoRA can match FullFT in simple tasks like sequence classification, instruction tuning, and chat after exact optimization of the hyperparameters.
LoRA struggles on difficult tasks like code and long-form text generation.
LoRA and FullFT yield weight matrices with very different structure. FullFT retains most of the pre-training structure while LoRA has a diagonal shift.
LoRA learn less and forget less (Biderman et al., 2024)¶
FullFT is more accurate and sample-efficient than LoRA, but LoRA forget less of the original knowledge.
FullFT is more accurate and sample-efficient than LoRA during continuous pre-training, but LoRA matches the FullFT performance with instruction-tuning.
LoRA forgets less of the original pre-trained knowledge.
LoRA helps maintaining the diversity of generation.
Conclusion on LoRA vs. FullFT¶
It is unclear whether LoRA can match FullFT.
The recommended solution is to use LoRA in budget-constrained scenarios!
Beyond LoRA¶
QLoRA (Quantized LoRA); DoRA (Weight-Decomposed LoRA); Mixture of LoRA Experts (MoLE); LongLoRA; ConvLoRA; AdaLoRA; QALoRA; ...
QLoRA (Quantized LoRA): quantizes the pre-trained weights to 4-bit precision while keeping the smaller LoRA matrices in full precision. During backpropagation the original weights are dequantized on-the-fly when needed. This approach achieves a GPU memory saving, at the cost of a increased runtime.
DoRA (Weight Decomposed LoRA): decouples the pre-trained weights into magnitude and direction. It then applied the LoRA update only to the directional component resulting in a accuracy improvement with minimal added parameters ().
Phi-4-Multimodal: uses separate dedicated LoRA adapters for different input types e.g., vision and audio. This parameter-efficient strategy allows a single LLM backbone to seamlessly integrate and process complex multimodal inputs without the cost of retraining the entire system for each new modality.
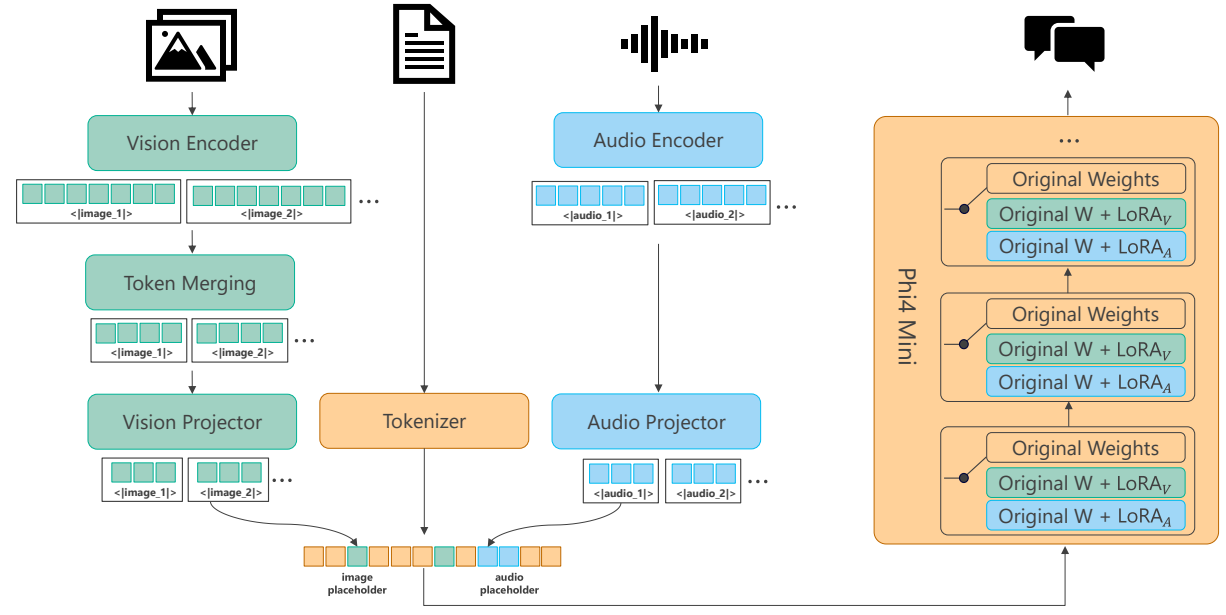
Figure: An overview of the multimodal architecture for Phi-4-Multimodal.
Source: Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs (Microsoft, 2025)
Useful material:¶
Stanford CME295 course. Transformers & LLMs. (Autumn 2025).
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
https://
machinelearningmastery .com /encoders -and -decoders -in -transformer -models/ Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
LoRA and Beyond. Fine-Tuning LLMs for Anyone, Anywhere. https://
amore -labs .github .io /website /notebooks /lora .html (2025). Shuttleworth, Reece, et al. “Lora vs full fine-tuning: An illusion of equivalence.” arXiv preprint arXiv:2410.21228 (2024).
Biderman, Dan, et al. “LoRA Learns Less and Forgets Less.” Transactions on Machine Learning Research. (2024)
Houlsby, Neil, et al. “Parameter-efficient transfer learning for NLP.” ICML (2019).
Abouelenin, Abdelrahman, et al. “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.” arXiv preprint arXiv:2503.01743 (2025).
Schulman, John and Thinking Machines Lab, “LoRA Without Regret”, Thinking Machines Lab: Connectionism, Sep 2025.
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation). Sebastian Raschka. 2023.
New LLM Pre-training and Post-training Paradigms. Sebastian Raschka. 2024.
Unsloth’s LoRA Hyperparameter Guide. https://
unsloth .ai /docs /get -started /fine -tuning -llms -guide /lora -hyperparameters -guide. Abouelenin, Abdelrahman, et al. “Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras.” arXiv preprint arXiv:2503.01743 (2025).
Dettmers, Tim, et al. “Qlora: Efficient finetuning of quantized llms.” NeurIPS (2023): 10088-10115.
Liu, Shih-Yang, et al. “Dora: Weight-decomposed low-rank adaptation.” Forty-first International Conference on Machine Learning. 2024.