Of course we are going to start with importing necessary libraries like we used to do. But this time (while working with NN and deep learning) Pytorch is going to be our best friend. It is a great library that Meta built, it allows enough customization but also user friendly with its built in functions as well.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
import time
from tqdm import tqdm
import copyThe next important thing that we should do is changing the device to cuda. We should be using GPU to run things faster. Otherwise, it will take more time.
#Set random seeds for reproducibility
torch.manual_seed(42)
np.random.seed(42)
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")Using device: cpu
For this example, we will work with CIFAR10 dataset. It is an vision dataset and has 10 different categories. Number of training samples are 50,000 and testing samples are 10,000. Each image is 32 x 32 pixels (so it is not huge).
# PART 1: DATA PREPARATION
# ========================================
print("="*50)
print("LOADING CIFAR-10 DATASET")
print("="*50)
# Data transformations
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Load CIFAR-10
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print(f"\nDataset Info:")
print(f"- Training samples: {len(trainset)}")
print(f"- Test samples: {len(testset)}")
print(f"- Image shape: 32x32x3 (RGB)")
print(f"- Flattened input size: {32*32*3} = 3072 features")
print(f"- Number of classes: 10")==================================================
LOADING CIFAR-10 DATASET
==================================================
Dataset Info:
- Training samples: 50000
- Test samples: 10000
- Image shape: 32x32x3 (RGB)
- Flattened input size: 3072 = 3072 features
- Number of classes: 10
# Visualize some training images
def show_images(dataloader, num_images=10):
dataiter = iter(dataloader)
images, labels = next(dataiter)
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
for i, ax in enumerate(axes.flat):
img = images[i].numpy().transpose((1, 2, 0))
img = img * 0.5 + 0.5 # Denormalize
ax.imshow(img)
ax.set_title(classes[labels[i]])
ax.axis('off')
plt.tight_layout()
plt.show()
print("\nSample images from CIFAR-10:")
show_images(trainloader)
Sample images from CIFAR-10:

Then we will define our MLP architecture. The input size must match with the flattened image size. So since we have 32 x 32 pixel with rgb we will have 32 x 32 x 3 = 3072 (each color will bring another dimension so it will be 3).
Then we can define hidden layer numbers. In this case we defined 2 layers with input 512 and 256 nodes repsectively. But adjusting it is very easy.
You can go through the every hyperparameter in the model definition and play with them.
class FlexibleMLP(nn.Module):
"""
One flexible MLP that we can configure for ALL experiments
"""
def __init__(self,
input_size=3072,
hidden_sizes=[512, 256],
num_classes=10,
activation='relu',
use_batchnorm=False,
dropout_rate=0.0,
init_method='kaiming'):
super(FlexibleMLP, self).__init__()
self.activation_name = activation
self.use_batchnorm = use_batchnorm
self.dropout_rate = dropout_rate
# Build layers dynamically
layers = []
prev_size = input_size
for i, hidden_size in enumerate(hidden_sizes):
# Linear layer
layers.append(nn.Linear(prev_size, hidden_size))
# Batch normalization (before activation)
if use_batchnorm:
layers.append(nn.BatchNorm1d(hidden_size))
# Activation function
layers.append(self._get_activation(activation))
# Dropout
if dropout_rate > 0:
layers.append(nn.Dropout(dropout_rate))
prev_size = hidden_size
# Output layer (no activation, CrossEntropyLoss applies softmax)
layers.append(nn.Linear(prev_size, num_classes))
self.network = nn.Sequential(*layers)
# Initialize weights
self._initialize_weights(init_method)
def _get_activation(self, name):
"""Return activation function by name"""
activations = {
'relu': nn.ReLU(),
'leaky_relu': nn.LeakyReLU(0.01),
'tanh': nn.Tanh(),
'sigmoid': nn.Sigmoid(),
'elu': nn.ELU(),
'gelu': nn.GELU()
}
return activations.get(name.lower(), nn.ReLU())
def _initialize_weights(self, method):
"""Initialize weights using specified method"""
for m in self.modules():
if isinstance(m, nn.Linear):
if method == 'zeros':
nn.init.zeros_(m.weight)
elif method == 'ones':
nn.init.ones_(m.weight)
elif method == 'normal':
nn.init.normal_(m.weight, mean=0, std=0.01)
elif method == 'xavier':
nn.init.xavier_uniform_(m.weight)
elif method == 'kaiming':
nn.init.kaiming_uniform_(m.weight, nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
def forward(self, x):
return self.network(x)
def count_parameters(self):
"""Count trainable parameters"""
return sum(p.numel() for p in self.parameters() if p.requires_grad)
# TRAINING FUNCTION WITH DETAILED METRICS
def train_and_evaluate(model,
trainloader,
testloader,
epochs=10,
lr=0.001,
optimizer_name='adam',
weight_decay=0,
scheduler_type=None,
track_gradients=False,
verbose=True):
criterion = nn.CrossEntropyLoss()
# Create optimizer
if optimizer_name.lower() == 'sgd':
optimizer = optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
elif optimizer_name.lower() == 'sgd_momentum':
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)
elif optimizer_name.lower() == 'adam':
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
elif optimizer_name.lower() == 'rmsprop':
optimizer = optim.RMSprop(model.parameters(), lr=lr, weight_decay=weight_decay)
else:
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
# Create scheduler if requested
scheduler = None
if scheduler_type == 'step':
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
elif scheduler_type == 'cosine':
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
# Tracking variables
history = {
'train_loss': [],
'train_acc': [],
'test_loss': [],
'test_acc': [],
'learning_rates': [],
'gradient_norms': [] if track_gradients else None,
'gradient_per_layer': [] if track_gradients else None
}
for epoch in range(epochs):
# ============ TRAINING ============
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
epoch_gradients = []
pbar = tqdm(trainloader, desc=f'Epoch {epoch+1}/{epochs}', disable=not verbose)
for batch_idx, (inputs, labels) in enumerate(pbar):
# Flatten images
inputs = inputs.view(inputs.size(0), -1)
inputs, labels = inputs.to(device), labels.to(device)
# Forward pass
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass
loss.backward()
# Track gradients
if track_gradients and batch_idx == 0: # Track first batch only
total_norm = 0
layer_grads = []
for p in model.parameters():
if p.grad is not None:
param_norm = p.grad.data.norm(2)
total_norm += param_norm.item() ** 2
layer_grads.append(p.grad.abs().mean().item())
total_norm = total_norm ** 0.5
epoch_gradients.append(total_norm)
if epoch == 0: # Save layer-wise gradients for first epoch
if history['gradient_per_layer'] is not None:
history['gradient_per_layer'] = layer_grads
optimizer.step()
# Track metrics
train_loss += loss.item()
_, predicted = outputs.max(1)
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
if verbose:
pbar.set_postfix({
'loss': f'{loss.item():.4f}',
'acc': f'{100.*train_correct/train_total:.2f}%'
})
# Calculate epoch training metrics
avg_train_loss = train_loss / len(trainloader)
train_accuracy = 100. * train_correct / train_total
history['train_loss'].append(avg_train_loss)
history['train_acc'].append(train_accuracy)
if track_gradients and len(epoch_gradients) > 0:
history['gradient_norms'].append(np.mean(epoch_gradients))
# ============ EVALUATION ============
model.eval()
test_loss = 0.0
test_correct = 0
test_total = 0
with torch.no_grad():
for inputs, labels in testloader:
inputs = inputs.view(inputs.size(0), -1)
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = outputs.max(1)
test_total += labels.size(0)
test_correct += predicted.eq(labels).sum().item()
avg_test_loss = test_loss / len(testloader)
test_accuracy = 100. * test_correct / test_total
history['test_loss'].append(avg_test_loss)
history['test_acc'].append(test_accuracy)
# Track learning rate
current_lr = optimizer.param_groups[0]['lr']
history['learning_rates'].append(current_lr)
# Update scheduler
if scheduler is not None:
scheduler.step()
if verbose:
print(f'Epoch {epoch+1}/{epochs} | '
f'Train Loss: {avg_train_loss:.4f} | '
f'Train Acc: {train_accuracy:.2f}% | '
f'Test Loss: {avg_test_loss:.4f} | '
f'Test Acc: {test_accuracy:.2f}%')
return historyExperiment 1: Activation Function and a Silent Killer
In the Experiment below, we will try different activation functions from sigmoid to Leaky Relu. We will observe the training vs test accuracies and select the winning activation.
# EXPERIMENT 1: ACTIVATION FUNCTIONS
print("\nWe'll test the SAME network architecture with different activations")
print("and PROVE why ReLU works better by tracking gradients!\n")
# Baseline configuration
BASE_CONFIG = {
'input_size': 3072,
'hidden_sizes': [256, 128],
'num_classes': 10,
'use_batchnorm': False,
'dropout_rate': 0.0,
'init_method': 'kaiming'
}
activations_to_test = ['sigmoid', 'tanh', 'relu', 'leaky_relu']
activation_results = {}
for activation in activations_to_test:
print(f"\n{'='*70}")
print(f"Testing: {activation.upper()} activation")
print(f"{'='*70}")
# Create model with only activation changed
model = FlexibleMLP(
**BASE_CONFIG,
activation=activation
).to(device)
print(f"Parameters: {model.count_parameters():,}")
# Train with gradient tracking
history = train_and_evaluate(
model, trainloader, testloader,
epochs=8,
lr=0.001,
optimizer_name='adam',
track_gradients=True,
verbose=True
)
activation_results[activation] = history
We'll test the SAME network architecture with different activations
and PROVE why ReLU works better by tracking gradients!
======================================================================
Testing: SIGMOID activation
======================================================================
Parameters: 820,874
Epoch 1/8: 100%|██████████| 391/391 [00:16<00:00, 23.38it/s, loss=1.7723, acc=38.30%]
Epoch 1/8 | Train Loss: 1.7584 | Train Acc: 38.30% | Test Loss: 1.6291 | Test Acc: 43.66%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.50it/s, loss=1.6326, acc=44.89%]
Epoch 2/8 | Train Loss: 1.5812 | Train Acc: 44.89% | Test Loss: 1.5565 | Test Acc: 46.13%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 30.46it/s, loss=1.5795, acc=48.21%]
Epoch 3/8 | Train Loss: 1.4870 | Train Acc: 48.21% | Test Loss: 1.5181 | Test Acc: 46.67%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 30.71it/s, loss=1.4101, acc=50.73%]
Epoch 4/8 | Train Loss: 1.4115 | Train Acc: 50.73% | Test Loss: 1.4721 | Test Acc: 48.50%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.78it/s, loss=1.6562, acc=53.24%]
Epoch 5/8 | Train Loss: 1.3497 | Train Acc: 53.24% | Test Loss: 1.4747 | Test Acc: 48.92%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 31.79it/s, loss=1.2309, acc=55.08%]
Epoch 6/8 | Train Loss: 1.2894 | Train Acc: 55.08% | Test Loss: 1.4513 | Test Acc: 49.89%
Epoch 7/8: 100%|██████████| 391/391 [00:13<00:00, 29.60it/s, loss=1.1540, acc=57.27%]
Epoch 7/8 | Train Loss: 1.2350 | Train Acc: 57.27% | Test Loss: 1.4416 | Test Acc: 49.84%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.39it/s, loss=1.2697, acc=59.25%]
Epoch 8/8 | Train Loss: 1.1815 | Train Acc: 59.25% | Test Loss: 1.4437 | Test Acc: 49.44%
======================================================================
Testing: TANH activation
======================================================================
Parameters: 820,874
Epoch 1/8: 100%|██████████| 391/391 [00:12<00:00, 30.23it/s, loss=1.7964, acc=38.19%]
Epoch 1/8 | Train Loss: 1.7803 | Train Acc: 38.19% | Test Loss: 1.6734 | Test Acc: 41.99%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.88it/s, loss=1.5326, acc=44.26%]
Epoch 2/8 | Train Loss: 1.6121 | Train Acc: 44.26% | Test Loss: 1.6212 | Test Acc: 43.13%
Epoch 3/8: 100%|██████████| 391/391 [00:13<00:00, 29.74it/s, loss=1.2605, acc=46.99%]
Epoch 3/8 | Train Loss: 1.5302 | Train Acc: 46.99% | Test Loss: 1.5798 | Test Acc: 45.33%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 30.48it/s, loss=1.4486, acc=49.08%]
Epoch 4/8 | Train Loss: 1.4681 | Train Acc: 49.08% | Test Loss: 1.5634 | Test Acc: 46.20%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.63it/s, loss=1.4853, acc=51.03%]
Epoch 5/8 | Train Loss: 1.4150 | Train Acc: 51.03% | Test Loss: 1.5479 | Test Acc: 46.98%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.25it/s, loss=1.4428, acc=52.79%]
Epoch 6/8 | Train Loss: 1.3712 | Train Acc: 52.79% | Test Loss: 1.5404 | Test Acc: 47.10%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.12it/s, loss=1.4668, acc=54.21%]
Epoch 7/8 | Train Loss: 1.3235 | Train Acc: 54.21% | Test Loss: 1.5339 | Test Acc: 47.19%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.31it/s, loss=1.3612, acc=55.63%]
Epoch 8/8 | Train Loss: 1.2811 | Train Acc: 55.63% | Test Loss: 1.5474 | Test Acc: 47.28%
======================================================================
Testing: RELU activation
======================================================================
Parameters: 820,874
Epoch 1/8: 100%|██████████| 391/391 [00:13<00:00, 29.24it/s, loss=1.3328, acc=40.39%]
Epoch 1/8 | Train Loss: 1.7032 | Train Acc: 40.39% | Test Loss: 1.5512 | Test Acc: 45.50%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.41it/s, loss=1.3367, acc=48.90%]
Epoch 2/8 | Train Loss: 1.4601 | Train Acc: 48.90% | Test Loss: 1.4539 | Test Acc: 49.33%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 30.50it/s, loss=1.2833, acc=52.97%]
Epoch 3/8 | Train Loss: 1.3444 | Train Acc: 52.97% | Test Loss: 1.4339 | Test Acc: 50.02%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 30.58it/s, loss=1.2951, acc=56.02%]
Epoch 4/8 | Train Loss: 1.2585 | Train Acc: 56.02% | Test Loss: 1.4309 | Test Acc: 50.94%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.28it/s, loss=1.0905, acc=58.17%]
Epoch 5/8 | Train Loss: 1.1907 | Train Acc: 58.17% | Test Loss: 1.4353 | Test Acc: 51.14%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.81it/s, loss=1.3432, acc=60.70%]
Epoch 6/8 | Train Loss: 1.1223 | Train Acc: 60.70% | Test Loss: 1.4109 | Test Acc: 51.37%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.54it/s, loss=1.3268, acc=62.68%]
Epoch 7/8 | Train Loss: 1.0587 | Train Acc: 62.68% | Test Loss: 1.4438 | Test Acc: 51.36%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.86it/s, loss=1.0404, acc=65.11%]
Epoch 8/8 | Train Loss: 0.9986 | Train Acc: 65.11% | Test Loss: 1.4215 | Test Acc: 52.44%
======================================================================
Testing: LEAKY_RELU activation
======================================================================
Parameters: 820,874
Epoch 1/8: 100%|██████████| 391/391 [00:13<00:00, 30.07it/s, loss=1.6875, acc=40.81%]
Epoch 1/8 | Train Loss: 1.6928 | Train Acc: 40.81% | Test Loss: 1.5323 | Test Acc: 45.59%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 31.24it/s, loss=1.3600, acc=48.96%]
Epoch 2/8 | Train Loss: 1.4514 | Train Acc: 48.96% | Test Loss: 1.4709 | Test Acc: 47.98%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 30.18it/s, loss=1.5958, acc=52.98%]
Epoch 3/8 | Train Loss: 1.3434 | Train Acc: 52.98% | Test Loss: 1.4497 | Test Acc: 48.82%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 30.76it/s, loss=1.5612, acc=55.77%]
Epoch 4/8 | Train Loss: 1.2597 | Train Acc: 55.77% | Test Loss: 1.4236 | Test Acc: 51.17%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.42it/s, loss=1.3218, acc=58.04%]
Epoch 5/8 | Train Loss: 1.1938 | Train Acc: 58.04% | Test Loss: 1.4054 | Test Acc: 51.22%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.63it/s, loss=1.4442, acc=60.41%]
Epoch 6/8 | Train Loss: 1.1240 | Train Acc: 60.41% | Test Loss: 1.4246 | Test Acc: 51.47%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.26it/s, loss=1.2014, acc=62.96%]
Epoch 7/8 | Train Loss: 1.0616 | Train Acc: 62.96% | Test Loss: 1.4531 | Test Acc: 51.46%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.14it/s, loss=1.0170, acc=64.75%]
Epoch 8/8 | Train Loss: 1.0041 | Train Acc: 64.75% | Test Loss: 1.4645 | Test Acc: 51.60%
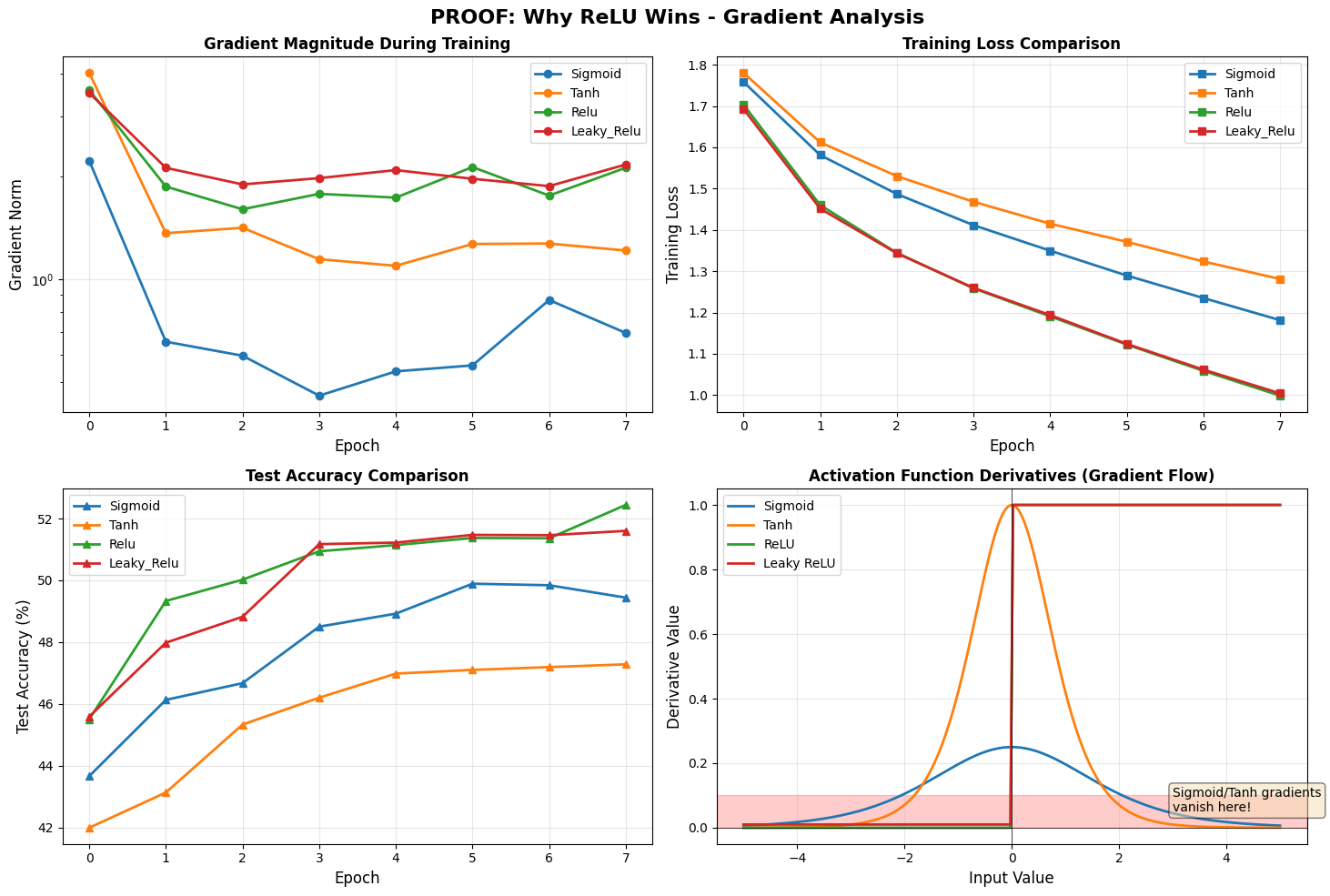
We have run different activations and now we want to clearly see what is going on with gradients when we change the activations.
# PROOF 1: WHY SIGMOID/TANH FAIL - GRADIENT ANALYSIS
# Show gradient magnitudes
print("\nGradient Norms Throughout Training:")
print("-" * 70)
print(f"{'Activation':<15} {'Epoch 1':<12} {'Epoch 4':<12} {'Epoch 8':<12}")
print("-" * 70)
for activation in activations_to_test:
grads = activation_results[activation]['gradient_norms']
print(f"{activation:<15} {grads[0]:<12.6f} {grads[3]:<12.6f} {grads[7]:<12.6f}")
print("Sigmoid/Tanh have SMALLER gradients → slower weight updates!")
print("ReLU/Leaky ReLU have LARGER gradients → faster learning!")
# Visualize gradient flow
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('PROOF: Why ReLU Wins - Gradient Analysis', fontsize=16, fontweight='bold')
# Plot 1: Gradient norms over training
ax = axes[0, 0]
for activation in activations_to_test:
grads = activation_results[activation]['gradient_norms']
ax.plot(grads, marker='o', label=activation.title(), linewidth=2)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Gradient Norm', fontsize=12)
ax.set_title('Gradient Magnitude During Training', fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_yscale('log')
# Plot 2: Training loss
ax = axes[0, 1]
for activation in activations_to_test:
loss = activation_results[activation]['train_loss']
ax.plot(loss, marker='s', label=activation.title(), linewidth=2)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Training Loss', fontsize=12)
ax.set_title('Training Loss Comparison', fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
# Plot 3: Test accuracy
ax = axes[1, 0]
for activation in activations_to_test:
acc = activation_results[activation]['test_acc']
ax.plot(acc, marker='^', label=activation.title(), linewidth=2)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Test Accuracy (%)', fontsize=12)
ax.set_title('Test Accuracy Comparison', fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
# Plot 4: Activation function derivatives
ax = axes[1, 1]
x = np.linspace(-5, 5, 200)
# Sigmoid derivative
sigmoid = 1 / (1 + np.exp(-x))
sigmoid_grad = sigmoid * (1 - sigmoid)
ax.plot(x, sigmoid_grad, label='Sigmoid', linewidth=2)
# Tanh derivative
tanh = np.tanh(x)
tanh_grad = 1 - tanh**2
ax.plot(x, tanh_grad, label='Tanh', linewidth=2)
# ReLU derivative
relu_grad = (x > 0).astype(float)
ax.plot(x, relu_grad, label='ReLU', linewidth=2)
# Leaky ReLU derivative
leaky_grad = np.where(x > 0, 1, 0.01)
ax.plot(x, leaky_grad, label='Leaky ReLU', linewidth=2)
ax.set_xlabel('Input Value', fontsize=12)
ax.set_ylabel('Derivative Value', fontsize=12)
ax.set_title('Activation Function Derivatives (Gradient Flow)', fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
ax.axhline(y=0, color='k', linewidth=0.5)
ax.axvline(x=0, color='k', linewidth=0.5)
# Highlight vanishing gradient region
ax.axhspan(0, 0.1, alpha=0.2, color='red', label='Vanishing Gradient Zone')
ax.text(3, 0.05, 'Sigmoid/Tanh gradients\nvanish here!', fontsize=10,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout()
plt.savefig('proof_activation_gradients.png', dpi=150, bbox_inches='tight')
plt.show()
Gradient Norms Throughout Training:
----------------------------------------------------------------------
Activation Epoch 1 Epoch 4 Epoch 8
----------------------------------------------------------------------
sigmoid 2.220008 0.455713 0.695523
tanh 4.014010 1.143375 1.212053
relu 3.574626 1.775860 2.117584
leaky_relu 3.505860 1.974570 2.163883
Sigmoid/Tanh have SMALLER gradients → slower weight updates!
ReLU/Leaky ReLU have LARGER gradients → faster learning!
Exercise 1.2 : Lets increase the depth and see what happens again
This have observed that ReLu is having higher gradients than the other activation functions. This time, we will increase the depth of the network and again evaluate each of them and ofcourse we will observe the changing gradients.
# PROOF 2: DEEP NETWORK - VANISHING GRADIENT
print("\nLet's make the network DEEPER (8 layers) and see what happens...")
print("We'll train 3 deep networks: Sigmoid, Tanh, and ReLU")
print("Hypothesis: Sigmoid/Tanh will fail or return worse results")
class DeepMLP(nn.Module):
"""Deep network where we can track each layer's gradients"""
def __init__(self, activation='sigmoid', depth=8, hidden_size=256):
super(DeepMLP, self).__init__()
self.layers = nn.ModuleList()
self.activation_name = activation
# Input layer
self.layers.append(nn.Linear(3072, hidden_size))
# Hidden layers
for _ in range(depth - 2):
self.layers.append(nn.Linear(hidden_size, hidden_size))
# Output layer
self.layers.append(nn.Linear(hidden_size, 10))
# Activation function
if activation == 'sigmoid':
self.activation = nn.Sigmoid()
elif activation == 'tanh':
self.activation = nn.Tanh()
elif activation == 'relu':
self.activation = nn.ReLU()
else:
self.activation = nn.ReLU()
# Initialize weights
for m in self.modules():
if isinstance(m, nn.Linear):
if activation in ['sigmoid', 'tanh']:
nn.init.xavier_uniform_(m.weight)
else:
nn.init.kaiming_uniform_(m.weight, nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
def forward(self, x):
for i, layer in enumerate(self.layers[:-1]):
x = self.activation(layer(x))
x = self.layers[-1](x) # No activation on output because we use cross entropy as a loss
return x
def count_parameters(self):
return sum(p.numel() for p in self.parameters() if p.requires_grad)
def analyze_layer_gradients(model, dataloader, device):
"""Get gradient magnitude for each layer"""
model.train()
criterion = nn.CrossEntropyLoss()
# Get one batch
inputs, labels = next(iter(dataloader))
inputs = inputs.view(inputs.size(0), -1)
inputs, labels = inputs.to(device), labels.to(device)
# Forward + backward
model.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
# Collect gradients per layer
layer_gradients = []
layer_names = []
for name, param in model.named_parameters():
if 'weight' in name and param.grad is not None:
grad_magnitude = param.grad.abs().mean().item()
layer_gradients.append(grad_magnitude)
layer_names.append(name)
return layer_gradients, layer_names
# Train deep networks with different activations
deep_activations = ['sigmoid', 'tanh', 'relu']
deep_results = {}
for activation in deep_activations:
print(f"\n{'='*70}")
print(f"Training DEEP network with {activation.upper()} activation")
print(f"{'='*70}")
model = DeepMLP(activation=activation, depth=8, hidden_size=256).to(device)
print(f"Parameters: {model.count_parameters():,}")
print(f"Architecture: 8 layers (1 input + 6 hidden + 1 output)")
# Analyze initial gradients (before training)
print("\nAnalyzing gradients BEFORE training...")
initial_grads, layer_names = analyze_layer_gradients(model, trainloader, device)
# Train the model
history = train_and_evaluate(
model, trainloader, testloader,
epochs=10,
lr=0.001,
optimizer_name='adam',
track_gradients=True,
verbose=True
)
# Analyze gradients after some training
print(f"\nAnalyzing gradients AFTER epoch 10")
trained_grads, _ = analyze_layer_gradients(model, trainloader, device)
deep_results[activation] = {
'history': history,
'initial_grads': initial_grads,
'trained_grads': trained_grads,
'layer_names': layer_names
}
# VISUALIZE THE PROOF
# Create comprehensive visualization
fig = plt.figure(figsize=(18, 12))
gs = fig.add_gridspec(3, 3, hspace=0.3, wspace=0.3)
# Main title
fig.suptitle('PROOF: Vanishing Gradient Problem in Deep Networks',
fontsize=18, fontweight='bold', y=0.98)
# Row 1: Layer-by-layer gradients
for idx, activation in enumerate(deep_activations):
ax = fig.add_subplot(gs[0, idx])
grads = deep_results[activation]['initial_grads']
layer_indices = list(range(len(grads)))
# Color code by gradient magnitude
colors = ['red' if g < 1e-5 else 'orange' if g < 1e-3 else 'green'
for g in grads]
bars = ax.bar(layer_indices, grads, color=colors, alpha=0.7,
edgecolor='black', linewidth=1.5)
ax.set_xlabel('Layer Index (0=first, 7=last)', fontsize=10)
ax.set_ylabel('Gradient Magnitude', fontsize=10)
ax.set_title(f'{activation.upper()}: Layer Gradients (Epoch 10)',
fontweight='bold', fontsize=11)
ax.set_yscale('log')
ax.grid(True, alpha=0.3, axis='y')
# Add threshold lines
ax.axhline(y=1e-5, color='red', linestyle='--', linewidth=2,
alpha=0.7, label='Dead Zone (<1e-5)')
ax.axhline(y=1e-3, color='orange', linestyle='--', linewidth=2,
alpha=0.7, label='Weak (<1e-3)')
# We can add emoji to make it more visual I guess
for i, grad in enumerate(grads):
if grad < 1e-5:
ax.text(i, grad, '💀', ha='center', fontsize=16,
va='bottom')
elif grad < 1e-3:
ax.text(i, grad, '😰', ha='center', fontsize=16,
va='bottom')
else:
ax.text(i, grad, '💪', ha='center', fontsize=16,
va='bottom')
if idx == 0:
ax.legend(fontsize=8, loc='upper right')
# Row 2: Training curves
# Training loss
ax_loss = fig.add_subplot(gs[1, :2])
for activation in deep_activations:
losses = deep_results[activation]['history']['train_loss']
ax_loss.plot(losses, marker='o', label=activation.upper(),
linewidth=2.5, markersize=6)
ax_loss.set_xlabel('Epoch', fontsize=12)
ax_loss.set_ylabel('Training Loss', fontsize=12)
ax_loss.set_title('Training Loss: Can They Learn?', fontweight='bold', fontsize=13)
ax_loss.legend(fontsize=11)
ax_loss.grid(True, alpha=0.3)
# Add annotations
sigmoid_final = deep_results['sigmoid']['history']['train_loss'][-1]
relu_final = deep_results['relu']['history']['train_loss'][-1]
if sigmoid_final > relu_final * 1.5:
ax_loss.annotate('Sigmoid struggles!',
xy=(9, sigmoid_final),
xytext=(7, sigmoid_final * 1.2),
arrowprops=dict(arrowstyle='->', color='red', lw=2),
fontsize=11, color='red', fontweight='bold')
ax_loss.annotate('ReLU learns fast!',
xy=(9, relu_final),
xytext=(6, relu_final * 1.5),
arrowprops=dict(arrowstyle='->', color='green', lw=2),
fontsize=11, color='green', fontweight='bold')
# Test accuracy
ax_acc = fig.add_subplot(gs[1, 2])
for activation in deep_activations:
accs = deep_results[activation]['history']['test_acc']
ax_acc.plot(accs, marker='s', label=activation.upper(),
linewidth=2.5, markersize=6)
ax_acc.set_xlabel('Epoch', fontsize=12)
ax_acc.set_ylabel('Test Accuracy (%)', fontsize=12)
ax_acc.set_title('Test Accuracy', fontweight='bold', fontsize=13)
ax_acc.legend(fontsize=11)
ax_acc.grid(True, alpha=0.3)
# Row 3: Gradient flow over time
ax_grad_flow = fig.add_subplot(gs[2, :])
for activation in deep_activations:
grad_norms = deep_results[activation]['history']['gradient_norms']
ax_grad_flow.plot(grad_norms, marker='d', label=activation.upper(),
linewidth=2.5, markersize=7)
ax_grad_flow.set_xlabel('Epoch', fontsize=12)
ax_grad_flow.set_ylabel('Average Gradient Norm', fontsize=12)
ax_grad_flow.set_title('Gradient Magnitude During Training (Higher = More Learning)',
fontweight='bold', fontsize=13)
ax_grad_flow.legend(fontsize=11)
ax_grad_flow.grid(True, alpha=0.3)
ax_grad_flow.set_yscale('log')
# Add threshold line
ax_grad_flow.axhline(y=1e-4, color='red', linestyle='--', linewidth=2,
alpha=0.7, label='Minimum for learning')
plt.savefig('proof_deep_vanishing_gradient_complete.png', dpi=150, bbox_inches='tight')
plt.show()
# NUMERICAL PROOF
for activation in deep_activations:
print(f"\n{activation.upper()} Network (8 layers):")
print("-" * 70)
print(f"{'Layer':<8} {'Initial Gradient':<20} {'Status':<20}")
print("-" * 70)
grads = deep_results[activation]['initial_grads']
for i, grad in enumerate(grads):
if grad < 1e-5:
status = "💀 DEAD (can't learn)"
elif grad < 1e-3:
status = "😰 VERY WEAK"
elif grad < 1e-2:
status = "😐 WEAK"
else:
status = "💪 STRONG"
print(f"Layer {i:<2} {grad:<20.2e} {status}")
# Calculate statistics
dead_layers = sum(1 for g in grads if g < 1e-5)
weak_layers = sum(1 for g in grads if 1e-5 <= g < 1e-3)
healthy_layers = sum(1 for g in grads if g >= 1e-3)
print("-" * 70)
print(f"Summary: {dead_layers} dead, {weak_layers} weak, {healthy_layers} healthy")
print("\n" + "="*70)
print("TRAINING PERFORMANCE COMPARISON")
print("="*70)
print(f"{'Activation':<12} {'Final Loss':<15} {'Final Accuracy':<15} {'Can Learn?'}")
print("-" * 70)
for activation in deep_activations:
final_loss = deep_results[activation]['history']['train_loss'][-1]
final_acc = deep_results[activation]['history']['test_acc'][-1]
# Determine if it learned successfully
if final_acc > 40:
can_learn = "✅ YES"
elif final_acc > 30:
can_learn = "⚠️ BARELY"
else:
can_learn = "❌ NO"
print(f"{activation.upper():<12} {final_loss:<15.4f} {final_acc:<15.2f}% {can_learn}")
print("=" * 70)
Let's make the network DEEPER (8 layers) and see what happens...
We'll train 3 deep networks: Sigmoid, Tanh, and ReLU
Hypothesis: Sigmoid/Tanh will fail or return worse results
======================================================================
Training DEEP network with SIGMOID activation
======================================================================
Parameters: 1,184,010
Architecture: 8 layers (1 input + 6 hidden + 1 output)
Analyzing gradients BEFORE training...
Epoch 1/10: 100%|██████████| 391/391 [00:13<00:00, 29.47it/s, loss=1.9599, acc=18.18%]
Epoch 1/10 | Train Loss: 2.1030 | Train Acc: 18.18% | Test Loss: 1.9959 | Test Acc: 22.99%
Epoch 2/10: 100%|██████████| 391/391 [00:13<00:00, 29.60it/s, loss=1.9299, acc=25.89%]
Epoch 2/10 | Train Loss: 1.9051 | Train Acc: 25.89% | Test Loss: 1.8390 | Test Acc: 30.33%
Epoch 3/10: 100%|██████████| 391/391 [00:13<00:00, 29.68it/s, loss=1.6902, acc=33.19%]
Epoch 3/10 | Train Loss: 1.7691 | Train Acc: 33.19% | Test Loss: 1.7444 | Test Acc: 34.10%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 29.61it/s, loss=1.7165, acc=37.72%]
Epoch 4/10 | Train Loss: 1.6780 | Train Acc: 37.72% | Test Loss: 1.6800 | Test Acc: 38.19%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 29.46it/s, loss=1.5809, acc=40.46%]
Epoch 5/10 | Train Loss: 1.6045 | Train Acc: 40.46% | Test Loss: 1.6453 | Test Acc: 39.02%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 29.75it/s, loss=1.4906, acc=42.90%]
Epoch 6/10 | Train Loss: 1.5467 | Train Acc: 42.90% | Test Loss: 1.5952 | Test Acc: 41.58%
Epoch 7/10: 100%|██████████| 391/391 [00:13<00:00, 29.74it/s, loss=1.4442, acc=45.11%]
Epoch 7/10 | Train Loss: 1.4973 | Train Acc: 45.11% | Test Loss: 1.5852 | Test Acc: 42.45%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 29.74it/s, loss=1.5046, acc=47.52%]
Epoch 8/10 | Train Loss: 1.4377 | Train Acc: 47.52% | Test Loss: 1.5521 | Test Acc: 44.08%
Epoch 9/10: 100%|██████████| 391/391 [00:13<00:00, 29.35it/s, loss=1.4092, acc=50.03%]
Epoch 9/10 | Train Loss: 1.3785 | Train Acc: 50.03% | Test Loss: 1.5845 | Test Acc: 44.31%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.51it/s, loss=1.3632, acc=51.72%]
Epoch 10/10 | Train Loss: 1.3336 | Train Acc: 51.72% | Test Loss: 1.5462 | Test Acc: 45.40%
Analyzing gradients AFTER epoch 10
======================================================================
Training DEEP network with TANH activation
======================================================================
Parameters: 1,184,010
Architecture: 8 layers (1 input + 6 hidden + 1 output)
Analyzing gradients BEFORE training...
Epoch 1/10: 100%|██████████| 391/391 [00:13<00:00, 29.25it/s, loss=1.8142, acc=36.70%]
Epoch 1/10 | Train Loss: 1.7963 | Train Acc: 36.70% | Test Loss: 1.6456 | Test Acc: 42.23%
Epoch 2/10: 100%|██████████| 391/391 [00:13<00:00, 29.56it/s, loss=1.7057, acc=43.21%]
Epoch 2/10 | Train Loss: 1.6104 | Train Acc: 43.21% | Test Loss: 1.5775 | Test Acc: 44.07%
Epoch 3/10: 100%|██████████| 391/391 [00:13<00:00, 29.35it/s, loss=1.7189, acc=45.93%]
Epoch 3/10 | Train Loss: 1.5285 | Train Acc: 45.93% | Test Loss: 1.5456 | Test Acc: 45.96%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 29.48it/s, loss=1.5843, acc=48.02%]
Epoch 4/10 | Train Loss: 1.4646 | Train Acc: 48.02% | Test Loss: 1.5227 | Test Acc: 46.44%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 29.15it/s, loss=1.4183, acc=49.89%]
Epoch 5/10 | Train Loss: 1.4159 | Train Acc: 49.89% | Test Loss: 1.5178 | Test Acc: 46.71%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 29.71it/s, loss=1.1463, acc=51.34%]
Epoch 6/10 | Train Loss: 1.3770 | Train Acc: 51.34% | Test Loss: 1.5138 | Test Acc: 47.43%
Epoch 7/10: 100%|██████████| 391/391 [00:13<00:00, 28.96it/s, loss=1.2080, acc=53.15%]
Epoch 7/10 | Train Loss: 1.3288 | Train Acc: 53.15% | Test Loss: 1.4794 | Test Acc: 48.59%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 29.24it/s, loss=1.3858, acc=54.71%]
Epoch 8/10 | Train Loss: 1.2817 | Train Acc: 54.71% | Test Loss: 1.4782 | Test Acc: 48.38%
Epoch 9/10: 100%|██████████| 391/391 [00:13<00:00, 29.21it/s, loss=1.1181, acc=55.46%]
Epoch 9/10 | Train Loss: 1.2491 | Train Acc: 55.46% | Test Loss: 1.4797 | Test Acc: 49.28%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.35it/s, loss=1.3800, acc=56.93%]
Epoch 10/10 | Train Loss: 1.2110 | Train Acc: 56.93% | Test Loss: 1.5055 | Test Acc: 48.47%
Analyzing gradients AFTER epoch 10
======================================================================
Training DEEP network with RELU activation
======================================================================
Parameters: 1,184,010
Architecture: 8 layers (1 input + 6 hidden + 1 output)
Analyzing gradients BEFORE training...
Epoch 1/10: 100%|██████████| 391/391 [00:13<00:00, 28.96it/s, loss=1.7869, acc=37.75%]
Epoch 1/10 | Train Loss: 1.7447 | Train Acc: 37.75% | Test Loss: 1.6136 | Test Acc: 42.50%
Epoch 2/10: 100%|██████████| 391/391 [00:13<00:00, 29.13it/s, loss=1.5017, acc=46.02%]
Epoch 2/10 | Train Loss: 1.5257 | Train Acc: 46.02% | Test Loss: 1.5173 | Test Acc: 45.96%
Epoch 3/10: 100%|██████████| 391/391 [00:13<00:00, 29.19it/s, loss=1.4964, acc=49.85%]
Epoch 3/10 | Train Loss: 1.4157 | Train Acc: 49.85% | Test Loss: 1.4301 | Test Acc: 49.88%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 29.23it/s, loss=1.2281, acc=53.05%]
Epoch 4/10 | Train Loss: 1.3236 | Train Acc: 53.05% | Test Loss: 1.4367 | Test Acc: 49.27%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 29.35it/s, loss=1.2516, acc=55.25%]
Epoch 5/10 | Train Loss: 1.2609 | Train Acc: 55.25% | Test Loss: 1.3923 | Test Acc: 51.01%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 28.91it/s, loss=1.1806, acc=57.96%]
Epoch 6/10 | Train Loss: 1.1873 | Train Acc: 57.96% | Test Loss: 1.3839 | Test Acc: 51.51%
Epoch 7/10: 100%|██████████| 391/391 [00:13<00:00, 29.10it/s, loss=1.1038, acc=60.04%]
Epoch 7/10 | Train Loss: 1.1280 | Train Acc: 60.04% | Test Loss: 1.3806 | Test Acc: 52.17%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 28.93it/s, loss=0.8346, acc=62.30%]
Epoch 8/10 | Train Loss: 1.0619 | Train Acc: 62.30% | Test Loss: 1.4003 | Test Acc: 52.09%
Epoch 9/10: 100%|██████████| 391/391 [00:13<00:00, 28.97it/s, loss=1.0443, acc=64.25%]
Epoch 9/10 | Train Loss: 1.0062 | Train Acc: 64.25% | Test Loss: 1.4340 | Test Acc: 51.79%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.11it/s, loss=1.1675, acc=66.46%]
Epoch 10/10 | Train Loss: 0.9481 | Train Acc: 66.46% | Test Loss: 1.4304 | Test Acc: 52.74%
Analyzing gradients AFTER epoch 10
/tmp/ipykernel_853/3592285382.py:239: UserWarning: Glyph 128128 (\N{SKULL}) missing from font(s) DejaVu Sans.
plt.savefig('proof_deep_vanishing_gradient_complete.png', dpi=150, bbox_inches='tight')
/tmp/ipykernel_853/3592285382.py:239: UserWarning: Glyph 128170 (\N{FLEXED BICEPS}) missing from font(s) DejaVu Sans.
plt.savefig('proof_deep_vanishing_gradient_complete.png', dpi=150, bbox_inches='tight')
/usr/local/lib/python3.12/dist-packages/IPython/core/pylabtools.py:151: UserWarning: Glyph 128128 (\N{SKULL}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
/usr/local/lib/python3.12/dist-packages/IPython/core/pylabtools.py:151: UserWarning: Glyph 128170 (\N{FLEXED BICEPS}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)
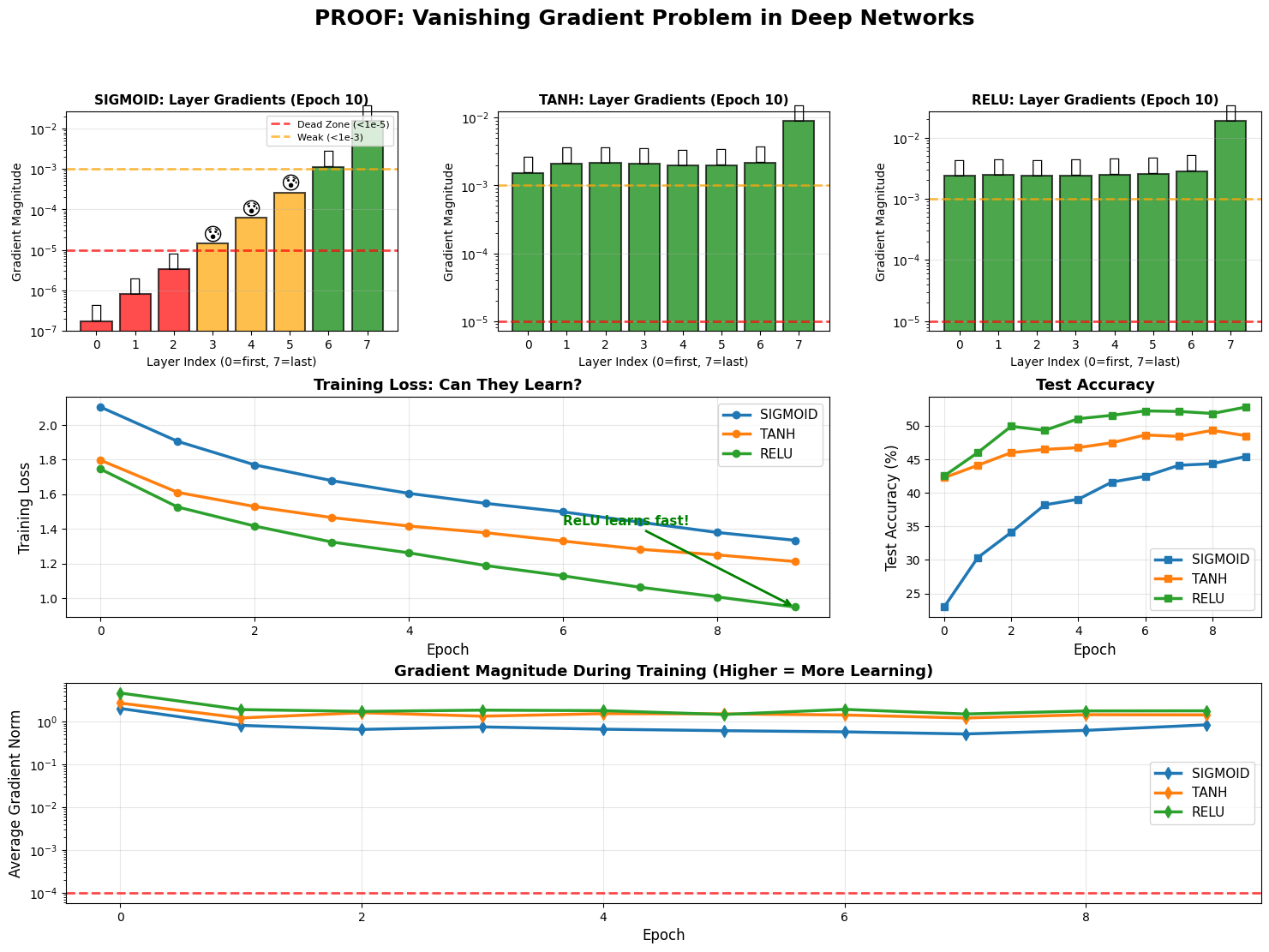
SIGMOID Network (8 layers):
----------------------------------------------------------------------
Layer Initial Gradient Status
----------------------------------------------------------------------
Layer 0 1.73e-07 💀 DEAD (can't learn)
Layer 1 7.97e-07 💀 DEAD (can't learn)
Layer 2 3.31e-06 💀 DEAD (can't learn)
Layer 3 1.44e-05 😰 VERY WEAK
Layer 4 6.14e-05 😰 VERY WEAK
Layer 5 2.61e-04 😰 VERY WEAK
Layer 6 1.12e-03 😐 WEAK
Layer 7 1.53e-02 💪 STRONG
----------------------------------------------------------------------
Summary: 3 dead, 3 weak, 2 healthy
TANH Network (8 layers):
----------------------------------------------------------------------
Layer Initial Gradient Status
----------------------------------------------------------------------
Layer 0 1.52e-03 😐 WEAK
Layer 1 2.11e-03 😐 WEAK
Layer 2 2.14e-03 😐 WEAK
Layer 3 2.07e-03 😐 WEAK
Layer 4 1.96e-03 😐 WEAK
Layer 5 1.97e-03 😐 WEAK
Layer 6 2.15e-03 😐 WEAK
Layer 7 8.87e-03 😐 WEAK
----------------------------------------------------------------------
Summary: 0 dead, 0 weak, 8 healthy
RELU Network (8 layers):
----------------------------------------------------------------------
Layer Initial Gradient Status
----------------------------------------------------------------------
Layer 0 2.35e-03 😐 WEAK
Layer 1 2.42e-03 😐 WEAK
Layer 2 2.35e-03 😐 WEAK
Layer 3 2.41e-03 😐 WEAK
Layer 4 2.47e-03 😐 WEAK
Layer 5 2.53e-03 😐 WEAK
Layer 6 2.82e-03 😐 WEAK
Layer 7 1.85e-02 💪 STRONG
----------------------------------------------------------------------
Summary: 0 dead, 0 weak, 8 healthy
======================================================================
TRAINING PERFORMANCE COMPARISON
======================================================================
Activation Final Loss Final Accuracy Can Learn?
----------------------------------------------------------------------
SIGMOID 1.3336 45.40 % ✅ YES
TANH 1.2110 48.47 % ✅ YES
RELU 0.9481 52.74 % ✅ YES
======================================================================
Exercise 2: Decide on the Optimizer
We have decided that the best activation is ReLu and are now confident that why this is the case.
Now we can see optimizer effects. This time we will analyze different optimizers with the same learning rate and see which one is the best choice for our case.
# EXPERIMENT 2: OPTIMIZERS
print("\nNow let's use the SAME model (ReLU activation) and ONLY change optimizer")
print("Everything else stays identical!\n")
# Use the best activation from Experiment 1
OPTIMIZED_CONFIG = {
**BASE_CONFIG,
'activation': 'relu' # Winner from Experiment 1
}
optimizers_to_test = [
('sgd', 0.001),
('sgd_momentum', 0.001),
('rmsprop', 0.001),
('adam', 0.001)
]
optimizer_results = {}
for opt_name, lr in optimizers_to_test:
print(f"\n{'='*70}")
print(f"Testing: {opt_name.upper()} optimizer (LR={lr})")
print(f"{'='*70}")
# Same model, different optimizer
model = FlexibleMLP(**OPTIMIZED_CONFIG).to(device)
history = train_and_evaluate(
model, trainloader, testloader,
epochs=10,
lr=lr,
optimizer_name=opt_name,
verbose=True
)
optimizer_results[opt_name] = history
# Visualize optimizer comparison
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
fig.suptitle('Optimizer Comparison (Same Model, Only Optimizer Changed)',
fontsize=16, fontweight='bold')
for opt_name, lr in optimizers_to_test:
ax1.plot(optimizer_results[opt_name]['train_loss'],
marker='o', label=opt_name.upper(), linewidth=2)
ax2.plot(optimizer_results[opt_name]['test_acc'],
marker='s', label=opt_name.upper(), linewidth=2)
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('Training Loss', fontsize=12)
ax1.set_title('Training Loss', fontweight='bold')
ax1.legend()
ax1.grid(True, alpha=0.3)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('Test Accuracy (%)', fontsize=12)
ax2.set_title('Test Accuracy', fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('optimizer_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
best_optimizer = max(optimizer_results.items(),
key=lambda x: x[1]['test_acc'][-1])
print(f"Best: {best_optimizer[0].upper()} with {best_optimizer[1]['test_acc'][-1]:.2f}% accuracy")
Now let's use the SAME model (ReLU activation) and ONLY change optimizer
Everything else stays identical!
======================================================================
Testing: SGD optimizer (LR=0.001)
======================================================================
Epoch 1/10: 100%|██████████| 391/391 [00:12<00:00, 30.23it/s, loss=2.1685, acc=18.99%]
Epoch 1/10 | Train Loss: 2.2188 | Train Acc: 18.99% | Test Loss: 2.0823 | Test Acc: 24.37%
Epoch 2/10: 100%|██████████| 391/391 [00:12<00:00, 30.74it/s, loss=1.9695, acc=27.41%]
Epoch 2/10 | Train Loss: 2.0202 | Train Acc: 27.41% | Test Loss: 1.9675 | Test Acc: 29.59%
Epoch 3/10: 100%|██████████| 391/391 [00:12<00:00, 30.47it/s, loss=1.8913, acc=31.17%]
Epoch 3/10 | Train Loss: 1.9304 | Train Acc: 31.17% | Test Loss: 1.8984 | Test Acc: 32.54%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 30.03it/s, loss=1.7654, acc=33.65%]
Epoch 4/10 | Train Loss: 1.8719 | Train Acc: 33.65% | Test Loss: 1.8515 | Test Acc: 34.45%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 28.18it/s, loss=1.7528, acc=35.39%]
Epoch 5/10 | Train Loss: 1.8293 | Train Acc: 35.39% | Test Loss: 1.8154 | Test Acc: 35.79%
Epoch 6/10: 100%|██████████| 391/391 [00:14<00:00, 27.34it/s, loss=1.9380, acc=36.76%]
Epoch 6/10 | Train Loss: 1.7962 | Train Acc: 36.76% | Test Loss: 1.7866 | Test Acc: 36.85%
Epoch 7/10: 100%|██████████| 391/391 [00:15<00:00, 25.43it/s, loss=1.6979, acc=37.87%]
Epoch 7/10 | Train Loss: 1.7686 | Train Acc: 37.87% | Test Loss: 1.7629 | Test Acc: 37.78%
Epoch 8/10: 100%|██████████| 391/391 [00:14<00:00, 26.74it/s, loss=1.7563, acc=38.80%]
Epoch 8/10 | Train Loss: 1.7454 | Train Acc: 38.80% | Test Loss: 1.7429 | Test Acc: 38.42%
Epoch 9/10: 100%|██████████| 391/391 [00:14<00:00, 27.36it/s, loss=1.5834, acc=39.60%]
Epoch 9/10 | Train Loss: 1.7249 | Train Acc: 39.60% | Test Loss: 1.7254 | Test Acc: 39.15%
Epoch 10/10: 100%|██████████| 391/391 [00:14<00:00, 27.22it/s, loss=1.7451, acc=40.29%]
Epoch 10/10 | Train Loss: 1.7071 | Train Acc: 40.29% | Test Loss: 1.7098 | Test Acc: 39.57%
======================================================================
Testing: SGD_MOMENTUM optimizer (LR=0.001)
======================================================================
Epoch 1/10: 100%|██████████| 391/391 [00:15<00:00, 24.96it/s, loss=1.7481, acc=32.86%]
Epoch 1/10 | Train Loss: 1.9015 | Train Acc: 32.86% | Test Loss: 1.7217 | Test Acc: 39.85%
Epoch 2/10: 100%|██████████| 391/391 [00:14<00:00, 27.86it/s, loss=1.6392, acc=42.02%]
Epoch 2/10 | Train Loss: 1.6634 | Train Acc: 42.02% | Test Loss: 1.6221 | Test Acc: 43.16%
Epoch 3/10: 100%|██████████| 391/391 [00:14<00:00, 27.78it/s, loss=1.7358, acc=45.06%]
Epoch 3/10 | Train Loss: 1.5773 | Train Acc: 45.06% | Test Loss: 1.5670 | Test Acc: 45.47%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 28.10it/s, loss=1.6443, acc=47.32%]
Epoch 4/10 | Train Loss: 1.5177 | Train Acc: 47.32% | Test Loss: 1.5276 | Test Acc: 46.49%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 27.97it/s, loss=1.4807, acc=49.11%]
Epoch 5/10 | Train Loss: 1.4701 | Train Acc: 49.11% | Test Loss: 1.5002 | Test Acc: 47.30%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 28.96it/s, loss=1.4865, acc=50.45%]
Epoch 6/10 | Train Loss: 1.4291 | Train Acc: 50.45% | Test Loss: 1.4820 | Test Acc: 47.62%
Epoch 7/10: 100%|██████████| 391/391 [00:13<00:00, 28.65it/s, loss=1.4571, acc=51.86%]
Epoch 7/10 | Train Loss: 1.3933 | Train Acc: 51.86% | Test Loss: 1.4588 | Test Acc: 48.90%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 28.79it/s, loss=1.4148, acc=53.10%]
Epoch 8/10 | Train Loss: 1.3610 | Train Acc: 53.10% | Test Loss: 1.4458 | Test Acc: 49.23%
Epoch 9/10: 100%|██████████| 391/391 [00:13<00:00, 28.99it/s, loss=1.2850, acc=54.17%]
Epoch 9/10 | Train Loss: 1.3304 | Train Acc: 54.17% | Test Loss: 1.4315 | Test Acc: 49.90%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.11it/s, loss=1.2431, acc=55.08%]
Epoch 10/10 | Train Loss: 1.3024 | Train Acc: 55.08% | Test Loss: 1.4134 | Test Acc: 50.33%
======================================================================
Testing: RMSPROP optimizer (LR=0.001)
======================================================================
Epoch 1/10: 100%|██████████| 391/391 [00:13<00:00, 29.25it/s, loss=1.4786, acc=38.41%]
Epoch 1/10 | Train Loss: 1.9211 | Train Acc: 38.41% | Test Loss: 1.6240 | Test Acc: 43.18%
Epoch 2/10: 100%|██████████| 391/391 [00:13<00:00, 29.16it/s, loss=1.5151, acc=47.12%]
Epoch 2/10 | Train Loss: 1.5072 | Train Acc: 47.12% | Test Loss: 1.5191 | Test Acc: 46.80%
Epoch 3/10: 100%|██████████| 391/391 [00:13<00:00, 28.92it/s, loss=1.4664, acc=51.09%]
Epoch 3/10 | Train Loss: 1.3876 | Train Acc: 51.09% | Test Loss: 1.4859 | Test Acc: 47.93%
Epoch 4/10: 100%|██████████| 391/391 [00:13<00:00, 29.35it/s, loss=1.4523, acc=54.46%]
Epoch 4/10 | Train Loss: 1.2982 | Train Acc: 54.46% | Test Loss: 1.4522 | Test Acc: 49.07%
Epoch 5/10: 100%|██████████| 391/391 [00:13<00:00, 29.62it/s, loss=1.6283, acc=57.47%]
Epoch 5/10 | Train Loss: 1.2165 | Train Acc: 57.47% | Test Loss: 1.4535 | Test Acc: 50.08%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 29.72it/s, loss=1.0087, acc=59.84%]
Epoch 6/10 | Train Loss: 1.1453 | Train Acc: 59.84% | Test Loss: 1.4450 | Test Acc: 50.58%
Epoch 7/10: 100%|██████████| 391/391 [00:13<00:00, 29.79it/s, loss=1.2140, acc=62.43%]
Epoch 7/10 | Train Loss: 1.0783 | Train Acc: 62.43% | Test Loss: 1.4917 | Test Acc: 49.68%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 29.75it/s, loss=1.3039, acc=64.23%]
Epoch 8/10 | Train Loss: 1.0183 | Train Acc: 64.23% | Test Loss: 1.4604 | Test Acc: 51.60%
Epoch 9/10: 100%|██████████| 391/391 [00:13<00:00, 29.95it/s, loss=0.8638, acc=66.39%]
Epoch 9/10 | Train Loss: 0.9579 | Train Acc: 66.39% | Test Loss: 1.5196 | Test Acc: 50.46%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.42it/s, loss=0.8095, acc=68.25%]
Epoch 10/10 | Train Loss: 0.9063 | Train Acc: 68.25% | Test Loss: 1.5276 | Test Acc: 51.23%
======================================================================
Testing: ADAM optimizer (LR=0.001)
======================================================================
Epoch 1/10: 100%|██████████| 391/391 [00:13<00:00, 29.58it/s, loss=1.5054, acc=40.22%]
Epoch 1/10 | Train Loss: 1.7045 | Train Acc: 40.22% | Test Loss: 1.5350 | Test Acc: 46.15%
Epoch 2/10: 100%|██████████| 391/391 [00:13<00:00, 29.93it/s, loss=1.4138, acc=48.71%]
Epoch 2/10 | Train Loss: 1.4604 | Train Acc: 48.71% | Test Loss: 1.4524 | Test Acc: 49.12%
Epoch 3/10: 100%|██████████| 391/391 [00:12<00:00, 30.86it/s, loss=1.5358, acc=53.08%]
Epoch 3/10 | Train Loss: 1.3483 | Train Acc: 53.08% | Test Loss: 1.4044 | Test Acc: 50.77%
Epoch 4/10: 100%|██████████| 391/391 [00:12<00:00, 30.14it/s, loss=1.4419, acc=55.54%]
Epoch 4/10 | Train Loss: 1.2619 | Train Acc: 55.54% | Test Loss: 1.4246 | Test Acc: 50.82%
Epoch 5/10: 100%|██████████| 391/391 [00:12<00:00, 30.37it/s, loss=1.2420, acc=58.33%]
Epoch 5/10 | Train Loss: 1.1886 | Train Acc: 58.33% | Test Loss: 1.4096 | Test Acc: 52.13%
Epoch 6/10: 100%|██████████| 391/391 [00:13<00:00, 29.82it/s, loss=1.2733, acc=60.93%]
Epoch 6/10 | Train Loss: 1.1215 | Train Acc: 60.93% | Test Loss: 1.4049 | Test Acc: 51.90%
Epoch 7/10: 100%|██████████| 391/391 [00:12<00:00, 30.40it/s, loss=1.3079, acc=62.93%]
Epoch 7/10 | Train Loss: 1.0554 | Train Acc: 62.93% | Test Loss: 1.4274 | Test Acc: 51.25%
Epoch 8/10: 100%|██████████| 391/391 [00:13<00:00, 30.02it/s, loss=0.8553, acc=64.97%]
Epoch 8/10 | Train Loss: 1.0017 | Train Acc: 64.97% | Test Loss: 1.4479 | Test Acc: 51.54%
Epoch 9/10: 100%|██████████| 391/391 [00:12<00:00, 30.43it/s, loss=1.0902, acc=66.66%]
Epoch 9/10 | Train Loss: 0.9496 | Train Acc: 66.66% | Test Loss: 1.4648 | Test Acc: 51.72%
Epoch 10/10: 100%|██████████| 391/391 [00:13<00:00, 29.77it/s, loss=0.7710, acc=68.45%]
Epoch 10/10 | Train Loss: 0.8933 | Train Acc: 68.45% | Test Loss: 1.4843 | Test Acc: 52.42%
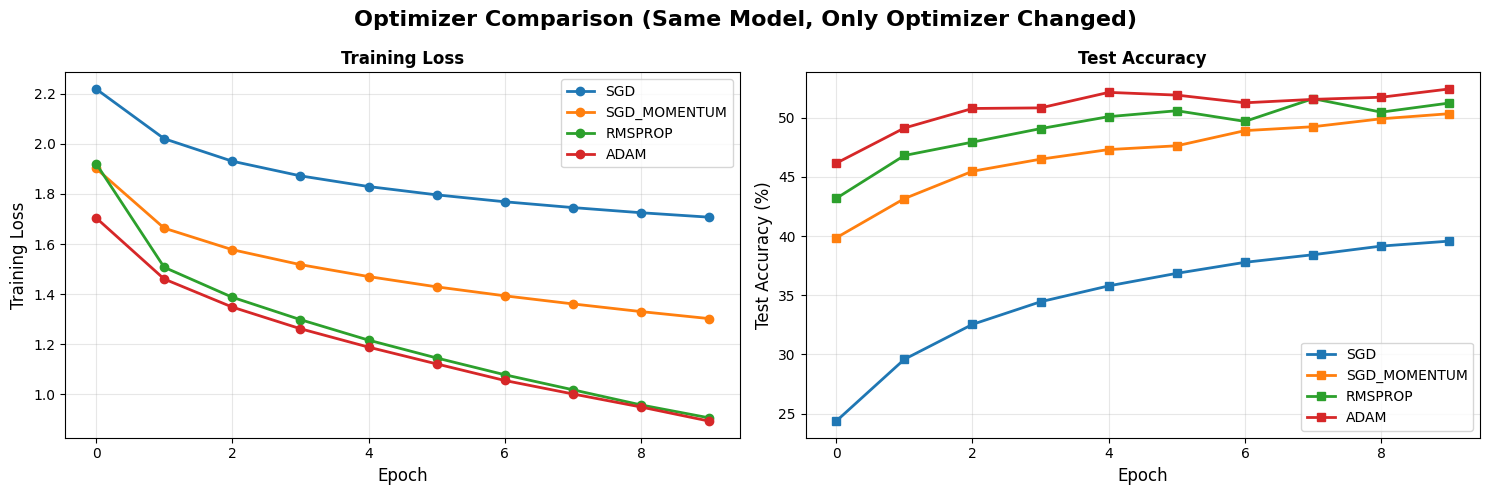
🎯 OPTIMIZER WINNER:
Best: ADAM with 52.42% accuracy
Exercise3: Learning rate schedulers
We found that the best optimizer is the ADAM for our case. But what about the learning rate?
We were experimenting with the fixed learning rate and assuming that it will be sufficient. But is this assumption holds true? Lets observe that in the below.
# EXPERIMENT 3: LEARNING RATE SCHEDULES
print("\nUsing best activation (ReLU) + best optimizer (Adam)")
print("Now we ONLY change the learning rate schedule\n")
# Use the best activation from Experiment 1
OPTIMIZED_CONFIG = {
**BASE_CONFIG,
'activation': 'relu' # Winner from Experiment 1
}
schedules_to_test = [
(None, 'Fixed LR'),
('step', 'Step Decay'),
('cosine', 'Cosine Annealing')
]
schedule_results = {}
for scheduler, name in schedules_to_test:
print(f"\n{'='*70}")
print(f"Testing: {name}")
print(f"{'='*70}")
model = FlexibleMLP(**OPTIMIZED_CONFIG).to(device)
history = train_and_evaluate(
model, trainloader, testloader,
epochs=15,
lr=0.001, # Higher initial LR for better visualization
optimizer_name='adam',
scheduler_type=scheduler,
verbose=True
)
schedule_results[name] = history
# Visualize
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
fig.suptitle('Learning Rate Schedule Comparison', fontsize=16, fontweight='bold')
for name in [s[1] for s in schedules_to_test]:
# LR schedule
axes[0].plot(schedule_results[name]['learning_rates'],
marker='o', label=name, linewidth=2)
# Train loss
axes[1].plot(schedule_results[name]['train_loss'],
marker='s', label=name, linewidth=2)
# Test accuracy
axes[2].plot(schedule_results[name]['test_acc'],
marker='^', label=name, linewidth=2)
axes[0].set_xlabel('Epoch', fontsize=12)
axes[0].set_ylabel('Learning Rate', fontsize=12)
axes[0].set_title('Learning Rate Schedule', fontweight='bold')
axes[0].set_yscale('log')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
axes[1].set_xlabel('Epoch', fontsize=12)
axes[1].set_ylabel('Training Loss', fontsize=12)
axes[1].set_title('Training Loss', fontweight='bold')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
axes[2].set_xlabel('Epoch', fontsize=12)
axes[2].set_ylabel('Test Accuracy (%)', fontsize=12)
axes[2].set_title('Test Accuracy', fontweight='bold')
axes[2].legend()
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('learning_rate_schedules.png', dpi=150, bbox_inches='tight')
plt.show()
Using best activation (ReLU) + best optimizer (Adam)
Now we ONLY change the learning rate schedule
======================================================================
Testing: Fixed LR
======================================================================
Epoch 1/15: 100%|██████████| 391/391 [00:23<00:00, 16.60it/s, loss=1.6582, acc=39.00%]
Epoch 1/15 | Train Loss: 1.7396 | Train Acc: 39.00% | Test Loss: 1.5569 | Test Acc: 44.49%
Epoch 2/15: 100%|██████████| 391/391 [00:23<00:00, 16.53it/s, loss=1.5205, acc=46.44%]
Epoch 2/15 | Train Loss: 1.5141 | Train Acc: 46.44% | Test Loss: 1.4657 | Test Acc: 47.29%
Epoch 3/15: 100%|██████████| 391/391 [00:21<00:00, 18.09it/s, loss=1.3213, acc=49.95%]
Epoch 3/15 | Train Loss: 1.4150 | Train Acc: 49.95% | Test Loss: 1.4506 | Test Acc: 48.55%
Epoch 4/15: 100%|██████████| 391/391 [00:20<00:00, 19.42it/s, loss=1.2592, acc=52.21%]
Epoch 4/15 | Train Loss: 1.3443 | Train Acc: 52.21% | Test Loss: 1.3913 | Test Acc: 50.99%
Epoch 5/15: 100%|██████████| 391/391 [00:21<00:00, 18.55it/s, loss=1.3756, acc=54.43%]
Epoch 5/15 | Train Loss: 1.2858 | Train Acc: 54.43% | Test Loss: 1.3824 | Test Acc: 51.18%
Epoch 6/15: 100%|██████████| 391/391 [00:21<00:00, 17.88it/s, loss=0.9660, acc=56.25%]
Epoch 6/15 | Train Loss: 1.2315 | Train Acc: 56.25% | Test Loss: 1.3702 | Test Acc: 52.23%
Epoch 7/15: 100%|██████████| 391/391 [00:20<00:00, 19.16it/s, loss=1.0173, acc=57.81%]
Epoch 7/15 | Train Loss: 1.1864 | Train Acc: 57.81% | Test Loss: 1.3805 | Test Acc: 51.81%
Epoch 8/15: 100%|██████████| 391/391 [00:21<00:00, 18.38it/s, loss=1.0908, acc=59.41%]
Epoch 8/15 | Train Loss: 1.1414 | Train Acc: 59.41% | Test Loss: 1.3706 | Test Acc: 52.96%
Epoch 9/15: 100%|██████████| 391/391 [00:21<00:00, 17.80it/s, loss=1.3220, acc=61.00%]
Epoch 9/15 | Train Loss: 1.0947 | Train Acc: 61.00% | Test Loss: 1.3843 | Test Acc: 52.31%
Epoch 10/15: 100%|██████████| 391/391 [00:22<00:00, 17.40it/s, loss=0.8033, acc=62.22%]
Epoch 10/15 | Train Loss: 1.0608 | Train Acc: 62.22% | Test Loss: 1.3980 | Test Acc: 52.81%
Epoch 11/15: 100%|██████████| 391/391 [00:20<00:00, 18.92it/s, loss=1.0639, acc=63.58%]
Epoch 11/15 | Train Loss: 1.0206 | Train Acc: 63.58% | Test Loss: 1.4157 | Test Acc: 52.52%
Epoch 12/15: 100%|██████████| 391/391 [00:20<00:00, 19.35it/s, loss=1.1356, acc=64.68%]
Epoch 12/15 | Train Loss: 0.9890 | Train Acc: 64.68% | Test Loss: 1.4265 | Test Acc: 52.43%
Epoch 13/15: 100%|██████████| 391/391 [00:21<00:00, 18.03it/s, loss=1.2926, acc=65.96%]
Epoch 13/15 | Train Loss: 0.9530 | Train Acc: 65.96% | Test Loss: 1.4353 | Test Acc: 52.88%
Epoch 14/15: 100%|██████████| 391/391 [00:21<00:00, 18.05it/s, loss=0.8143, acc=67.00%]
Epoch 14/15 | Train Loss: 0.9264 | Train Acc: 67.00% | Test Loss: 1.4249 | Test Acc: 53.17%
Epoch 15/15: 100%|██████████| 391/391 [00:20<00:00, 19.14it/s, loss=0.9030, acc=67.98%]
Epoch 15/15 | Train Loss: 0.8933 | Train Acc: 67.98% | Test Loss: 1.4568 | Test Acc: 52.67%
======================================================================
Testing: Step Decay
======================================================================
Epoch 1/15: 100%|██████████| 391/391 [00:20<00:00, 18.67it/s, loss=1.6737, acc=39.02%]
Epoch 1/15 | Train Loss: 1.7330 | Train Acc: 39.02% | Test Loss: 1.5433 | Test Acc: 45.43%
Epoch 2/15: 100%|██████████| 391/391 [00:21<00:00, 17.81it/s, loss=1.5308, acc=46.29%]
Epoch 2/15 | Train Loss: 1.5196 | Train Acc: 46.29% | Test Loss: 1.4705 | Test Acc: 48.13%
Epoch 3/15: 100%|██████████| 391/391 [00:22<00:00, 17.11it/s, loss=1.4926, acc=50.01%]
Epoch 3/15 | Train Loss: 1.4175 | Train Acc: 50.01% | Test Loss: 1.4284 | Test Acc: 49.72%
Epoch 4/15: 100%|██████████| 391/391 [00:21<00:00, 18.61it/s, loss=1.3715, acc=52.64%]
Epoch 4/15 | Train Loss: 1.3404 | Train Acc: 52.64% | Test Loss: 1.3888 | Test Acc: 50.69%
Epoch 5/15: 100%|██████████| 391/391 [00:20<00:00, 18.63it/s, loss=1.1696, acc=54.92%]
Epoch 5/15 | Train Loss: 1.2732 | Train Acc: 54.92% | Test Loss: 1.3906 | Test Acc: 50.97%
Epoch 6/15: 100%|██████████| 391/391 [00:22<00:00, 17.63it/s, loss=1.0659, acc=59.58%]
Epoch 6/15 | Train Loss: 1.1434 | Train Acc: 59.58% | Test Loss: 1.3369 | Test Acc: 52.99%
Epoch 7/15: 100%|██████████| 391/391 [00:22<00:00, 17.74it/s, loss=0.9872, acc=61.06%]
Epoch 7/15 | Train Loss: 1.0994 | Train Acc: 61.06% | Test Loss: 1.3371 | Test Acc: 53.52%
Epoch 8/15: 100%|██████████| 391/391 [00:20<00:00, 19.02it/s, loss=1.1243, acc=62.77%]
Epoch 8/15 | Train Loss: 1.0563 | Train Acc: 62.77% | Test Loss: 1.3397 | Test Acc: 53.36%
Epoch 9/15: 100%|██████████| 391/391 [00:20<00:00, 18.66it/s, loss=1.0285, acc=63.75%]
Epoch 9/15 | Train Loss: 1.0275 | Train Acc: 63.75% | Test Loss: 1.3403 | Test Acc: 53.49%
Epoch 10/15: 100%|██████████| 391/391 [00:22<00:00, 17.29it/s, loss=1.2144, acc=64.83%]
Epoch 10/15 | Train Loss: 0.9908 | Train Acc: 64.83% | Test Loss: 1.3481 | Test Acc: 53.59%
Epoch 11/15: 100%|██████████| 391/391 [00:22<00:00, 17.22it/s, loss=0.8405, acc=68.20%]
Epoch 11/15 | Train Loss: 0.9014 | Train Acc: 68.20% | Test Loss: 1.3324 | Test Acc: 54.17%
Epoch 12/15: 100%|██████████| 391/391 [00:21<00:00, 18.46it/s, loss=0.7606, acc=69.30%]
Epoch 12/15 | Train Loss: 0.8698 | Train Acc: 69.30% | Test Loss: 1.3514 | Test Acc: 53.83%
Epoch 13/15: 100%|██████████| 391/391 [00:20<00:00, 18.90it/s, loss=0.9040, acc=69.98%]
Epoch 13/15 | Train Loss: 0.8487 | Train Acc: 69.98% | Test Loss: 1.3597 | Test Acc: 54.41%
Epoch 14/15: 100%|██████████| 391/391 [00:21<00:00, 17.84it/s, loss=0.8004, acc=70.67%]
Epoch 14/15 | Train Loss: 0.8266 | Train Acc: 70.67% | Test Loss: 1.3568 | Test Acc: 54.40%
Epoch 15/15: 100%|██████████| 391/391 [00:23<00:00, 16.98it/s, loss=0.8988, acc=71.39%]
Epoch 15/15 | Train Loss: 0.8040 | Train Acc: 71.39% | Test Loss: 1.3782 | Test Acc: 54.53%
======================================================================
Testing: Cosine Annealing
======================================================================
Epoch 1/15: 100%|██████████| 391/391 [00:23<00:00, 16.73it/s, loss=1.5112, acc=39.09%]
Epoch 1/15 | Train Loss: 1.7382 | Train Acc: 39.09% | Test Loss: 1.5513 | Test Acc: 45.50%
Epoch 2/15: 100%|██████████| 391/391 [00:20<00:00, 19.05it/s, loss=1.3760, acc=46.99%]
Epoch 2/15 | Train Loss: 1.5104 | Train Acc: 46.99% | Test Loss: 1.4614 | Test Acc: 48.68%
Epoch 3/15: 100%|██████████| 391/391 [00:20<00:00, 18.76it/s, loss=1.3105, acc=50.32%]
Epoch 3/15 | Train Loss: 1.4047 | Train Acc: 50.32% | Test Loss: 1.4378 | Test Acc: 49.65%
Epoch 4/15: 100%|██████████| 391/391 [00:22<00:00, 17.57it/s, loss=1.3967, acc=53.13%]
Epoch 4/15 | Train Loss: 1.3281 | Train Acc: 53.13% | Test Loss: 1.4002 | Test Acc: 50.97%
Epoch 5/15: 100%|██████████| 391/391 [00:23<00:00, 16.80it/s, loss=1.1697, acc=55.60%]
Epoch 5/15 | Train Loss: 1.2581 | Train Acc: 55.60% | Test Loss: 1.3832 | Test Acc: 51.60%
Epoch 6/15: 100%|██████████| 391/391 [00:20<00:00, 19.11it/s, loss=1.2010, acc=58.05%]
Epoch 6/15 | Train Loss: 1.1892 | Train Acc: 58.05% | Test Loss: 1.3589 | Test Acc: 52.82%
Epoch 7/15: 100%|██████████| 391/391 [00:20<00:00, 19.02it/s, loss=1.1570, acc=60.32%]
Epoch 7/15 | Train Loss: 1.1250 | Train Acc: 60.32% | Test Loss: 1.3523 | Test Acc: 53.16%
Epoch 8/15: 100%|██████████| 391/391 [00:22<00:00, 17.71it/s, loss=1.2094, acc=62.50%]
Epoch 8/15 | Train Loss: 1.0602 | Train Acc: 62.50% | Test Loss: 1.3378 | Test Acc: 53.78%
Epoch 9/15: 100%|██████████| 391/391 [00:21<00:00, 18.26it/s, loss=0.7643, acc=64.45%]
Epoch 9/15 | Train Loss: 1.0015 | Train Acc: 64.45% | Test Loss: 1.3391 | Test Acc: 54.64%
Epoch 10/15: 100%|██████████| 391/391 [00:20<00:00, 18.89it/s, loss=1.0188, acc=66.67%]
Epoch 10/15 | Train Loss: 0.9440 | Train Acc: 66.67% | Test Loss: 1.3317 | Test Acc: 54.26%
Epoch 11/15: 100%|██████████| 391/391 [00:21<00:00, 18.17it/s, loss=0.8155, acc=68.68%]
Epoch 11/15 | Train Loss: 0.8947 | Train Acc: 68.68% | Test Loss: 1.3336 | Test Acc: 55.15%
Epoch 12/15: 100%|██████████| 391/391 [00:22<00:00, 17.40it/s, loss=0.9438, acc=70.08%]
Epoch 12/15 | Train Loss: 0.8483 | Train Acc: 70.08% | Test Loss: 1.3327 | Test Acc: 55.25%
Epoch 13/15: 100%|██████████| 391/391 [00:22<00:00, 17.73it/s, loss=0.7323, acc=71.62%]
Epoch 13/15 | Train Loss: 0.8126 | Train Acc: 71.62% | Test Loss: 1.3377 | Test Acc: 55.39%
Epoch 14/15: 100%|██████████| 391/391 [00:20<00:00, 18.79it/s, loss=0.7242, acc=72.45%]
Epoch 14/15 | Train Loss: 0.7891 | Train Acc: 72.45% | Test Loss: 1.3377 | Test Acc: 55.60%
Epoch 15/15: 100%|██████████| 391/391 [00:21<00:00, 18.57it/s, loss=0.8447, acc=72.94%]
Epoch 15/15 | Train Loss: 0.7739 | Train Acc: 72.94% | Test Loss: 1.3374 | Test Acc: 55.59%
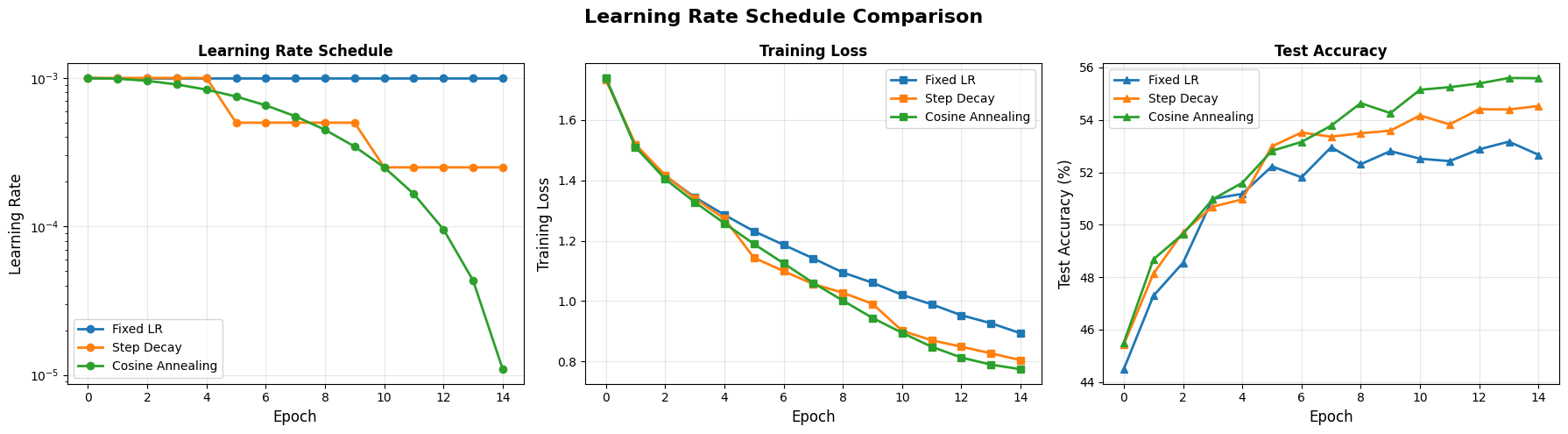
Exercise 4: Weight Initialization
Okaay, so far we have decided the best activation (ReLu), best optimizer(Adam) and found a better choice for learning rate for better training(cosine decay). Lets go back to beginning and try out different weight initializations.
# EXPERIMENT 4: WEIGHT INITIALIZATION
print("\nUsing best: ReLU + Adam + Cosine Schedule")
print("Now we ONLY change initialization method\n")
# Update config with best choices so far
BEST_CONFIG_SO_FAR = {
**BASE_CONFIG,
'activation': 'relu',
}
BEST_CONFIG_SO_FAR.pop('init_method', None)
inits_to_test = [
('zeros', 'Zeros'),
('normal', 'Normal'),
('xavier', 'Xavier'),
('kaiming', 'Kaiming')
]
init_results = {}
for init_method, name in inits_to_test:
print(f"\n{'='*70}")
print(f"Testing: {name}")
print(f"{'='*70}")
model = FlexibleMLP(
**BEST_CONFIG_SO_FAR,
init_method=init_method
).to(device)
history = train_and_evaluate(
model, trainloader, testloader,
epochs=8,
lr=0.01,
optimizer_name='adam',
scheduler_type='cosine',
verbose=True
)
init_results[name] = history
# Visualize
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
fig.suptitle('Weight Initialization Comparison', fontsize=16, fontweight='bold')
for init_method, name in inits_to_test:
ax1.plot(init_results[name]['train_loss'],
marker='o', label=name, linewidth=2)
ax2.plot(init_results[name]['test_acc'],
marker='s', label=name, linewidth=2)
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('Training Loss', fontsize=12)
ax1.set_title('Training Loss', fontweight='bold')
ax1.legend()
ax1.grid(True, alpha=0.3)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('Test Accuracy (%)', fontsize=12)
ax2.set_title('Test Accuracy', fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('weight_initialization.png', dpi=150, bbox_inches='tight')
plt.show()
Using best: ReLU + Adam + Cosine Schedule
Now we ONLY change initialization method
======================================================================
Testing: Zeros
======================================================================
Epoch 1/8: 100%|██████████| 391/391 [00:12<00:00, 30.31it/s, loss=2.2950, acc=9.81%]
Epoch 1/8 | Train Loss: 2.3035 | Train Acc: 9.81% | Test Loss: 2.3034 | Test Acc: 10.00%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.57it/s, loss=2.3066, acc=9.98%]
Epoch 2/8 | Train Loss: 2.3033 | Train Acc: 9.98% | Test Loss: 2.3030 | Test Acc: 10.00%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 30.60it/s, loss=2.2944, acc=9.94%]
Epoch 3/8 | Train Loss: 2.3032 | Train Acc: 9.94% | Test Loss: 2.3031 | Test Acc: 10.00%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 31.90it/s, loss=2.3027, acc=9.99%]
Epoch 4/8 | Train Loss: 2.3031 | Train Acc: 9.99% | Test Loss: 2.3031 | Test Acc: 10.00%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.65it/s, loss=2.3029, acc=9.92%]
Epoch 5/8 | Train Loss: 2.3030 | Train Acc: 9.92% | Test Loss: 2.3028 | Test Acc: 10.00%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.63it/s, loss=2.3026, acc=9.78%]
Epoch 6/8 | Train Loss: 2.3029 | Train Acc: 9.78% | Test Loss: 2.3027 | Test Acc: 10.00%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.35it/s, loss=2.3019, acc=9.89%]
Epoch 7/8 | Train Loss: 2.3028 | Train Acc: 9.89% | Test Loss: 2.3026 | Test Acc: 10.00%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.92it/s, loss=2.3031, acc=9.80%]
Epoch 8/8 | Train Loss: 2.3026 | Train Acc: 9.80% | Test Loss: 2.3026 | Test Acc: 10.00%
======================================================================
Testing: Normal
======================================================================
Epoch 1/8: 100%|██████████| 391/391 [00:12<00:00, 30.90it/s, loss=1.8818, acc=32.55%]
Epoch 1/8 | Train Loss: 1.8762 | Train Acc: 32.55% | Test Loss: 1.8052 | Test Acc: 36.59%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.93it/s, loss=1.7379, acc=36.32%]
Epoch 2/8 | Train Loss: 1.7808 | Train Acc: 36.32% | Test Loss: 1.7772 | Test Acc: 36.83%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 31.03it/s, loss=1.8208, acc=40.22%]
Epoch 3/8 | Train Loss: 1.6880 | Train Acc: 40.22% | Test Loss: 1.6927 | Test Acc: 39.03%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 32.29it/s, loss=1.5885, acc=43.80%]
Epoch 4/8 | Train Loss: 1.5727 | Train Acc: 43.80% | Test Loss: 1.6495 | Test Acc: 42.99%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.67it/s, loss=1.5717, acc=47.77%]
Epoch 5/8 | Train Loss: 1.4606 | Train Acc: 47.77% | Test Loss: 1.5963 | Test Acc: 44.04%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.68it/s, loss=1.3303, acc=51.79%]
Epoch 6/8 | Train Loss: 1.3488 | Train Acc: 51.79% | Test Loss: 1.5278 | Test Acc: 47.81%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.72it/s, loss=1.0526, acc=55.71%]
Epoch 7/8 | Train Loss: 1.2369 | Train Acc: 55.71% | Test Loss: 1.5031 | Test Acc: 49.17%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.88it/s, loss=1.1064, acc=58.54%]
Epoch 8/8 | Train Loss: 1.1543 | Train Acc: 58.54% | Test Loss: 1.4773 | Test Acc: 49.90%
======================================================================
Testing: Xavier
======================================================================
Epoch 1/8: 100%|██████████| 391/391 [00:13<00:00, 29.95it/s, loss=1.8690, acc=29.12%]
Epoch 1/8 | Train Loss: 2.0489 | Train Acc: 29.12% | Test Loss: 1.7515 | Test Acc: 36.55%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.75it/s, loss=1.5834, acc=38.95%]
Epoch 2/8 | Train Loss: 1.6996 | Train Acc: 38.95% | Test Loss: 1.6394 | Test Acc: 40.45%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 31.18it/s, loss=1.5919, acc=42.70%]
Epoch 3/8 | Train Loss: 1.6059 | Train Acc: 42.70% | Test Loss: 1.5842 | Test Acc: 43.85%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 30.86it/s, loss=1.5555, acc=45.85%]
Epoch 4/8 | Train Loss: 1.5165 | Train Acc: 45.85% | Test Loss: 1.5822 | Test Acc: 44.12%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.45it/s, loss=1.4155, acc=49.44%]
Epoch 5/8 | Train Loss: 1.4157 | Train Acc: 49.44% | Test Loss: 1.4969 | Test Acc: 47.43%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.80it/s, loss=1.2480, acc=53.51%]
Epoch 6/8 | Train Loss: 1.3033 | Train Acc: 53.51% | Test Loss: 1.4831 | Test Acc: 48.39%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.25it/s, loss=1.1939, acc=57.49%]
Epoch 7/8 | Train Loss: 1.1932 | Train Acc: 57.49% | Test Loss: 1.4087 | Test Acc: 51.09%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 31.17it/s, loss=1.2241, acc=60.67%]
Epoch 8/8 | Train Loss: 1.1011 | Train Acc: 60.67% | Test Loss: 1.4076 | Test Acc: 51.57%
======================================================================
Testing: Kaiming
======================================================================
Epoch 1/8: 100%|██████████| 391/391 [00:12<00:00, 30.48it/s, loss=1.7564, acc=29.57%]
Epoch 1/8 | Train Loss: 2.1472 | Train Acc: 29.57% | Test Loss: 1.7855 | Test Acc: 34.52%
Epoch 2/8: 100%|██████████| 391/391 [00:12<00:00, 30.74it/s, loss=1.6199, acc=39.45%]
Epoch 2/8 | Train Loss: 1.6916 | Train Acc: 39.45% | Test Loss: 1.6827 | Test Acc: 40.25%
Epoch 3/8: 100%|██████████| 391/391 [00:12<00:00, 31.56it/s, loss=1.6935, acc=43.23%]
Epoch 3/8 | Train Loss: 1.5953 | Train Acc: 43.23% | Test Loss: 1.6479 | Test Acc: 42.34%
Epoch 4/8: 100%|██████████| 391/391 [00:12<00:00, 31.36it/s, loss=1.7535, acc=46.47%]
Epoch 4/8 | Train Loss: 1.5048 | Train Acc: 46.47% | Test Loss: 1.6390 | Test Acc: 42.54%
Epoch 5/8: 100%|██████████| 391/391 [00:12<00:00, 30.73it/s, loss=1.7729, acc=49.73%]
Epoch 5/8 | Train Loss: 1.4208 | Train Acc: 49.73% | Test Loss: 1.5033 | Test Acc: 46.90%
Epoch 6/8: 100%|██████████| 391/391 [00:12<00:00, 30.93it/s, loss=1.4689, acc=54.01%]
Epoch 6/8 | Train Loss: 1.2955 | Train Acc: 54.01% | Test Loss: 1.4426 | Test Acc: 50.40%
Epoch 7/8: 100%|██████████| 391/391 [00:12<00:00, 30.74it/s, loss=1.2280, acc=57.99%]
Epoch 7/8 | Train Loss: 1.1816 | Train Acc: 57.99% | Test Loss: 1.4103 | Test Acc: 52.04%
Epoch 8/8: 100%|██████████| 391/391 [00:12<00:00, 30.92it/s, loss=0.9621, acc=61.56%]
Epoch 8/8 | Train Loss: 1.0857 | Train Acc: 61.56% | Test Loss: 1.3993 | Test Acc: 52.25%
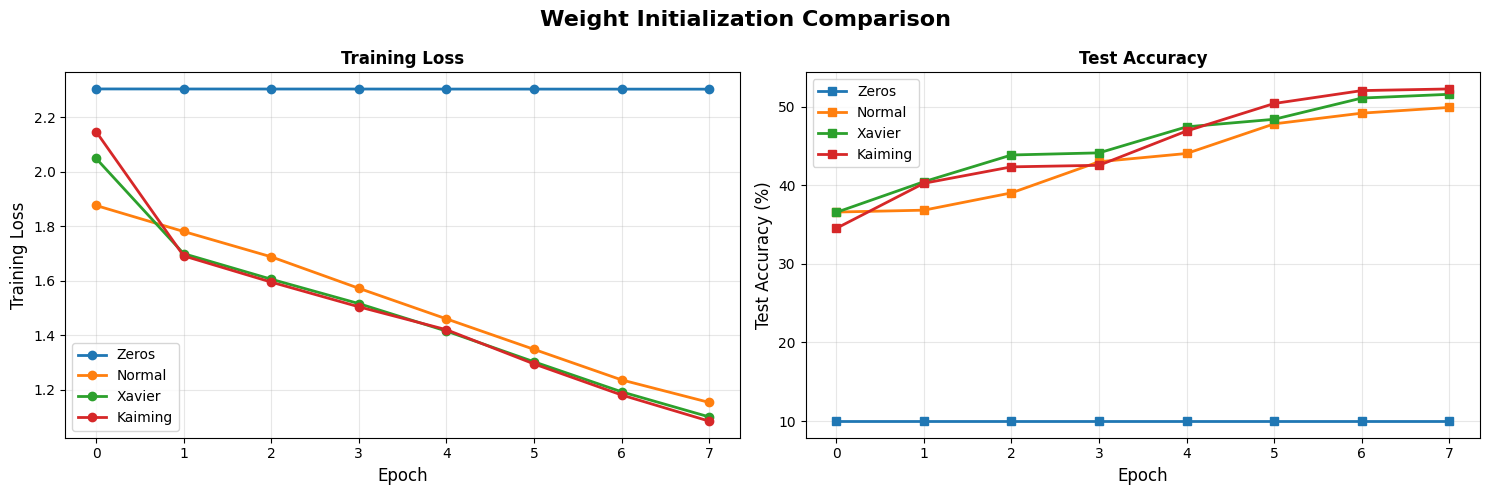
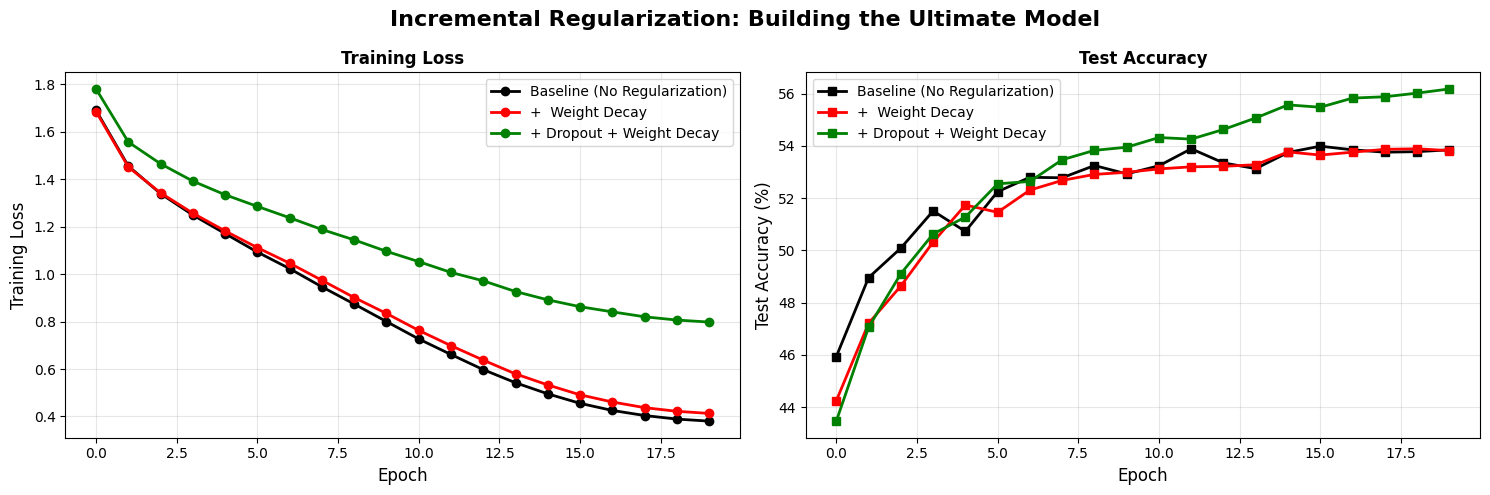
Exercise 5: Regularization
Since we have a better intialization, I think we can start talking about the small but huge tricks. I am talking about the regularization, batch normalization.
# EXPERIMENT 5: REGULARIZATION
print("\n" + "="*70)
print("EXPERIMENT 5: Regularization - Building the Ultimate Model")
print("="*70)
# Baseline configuration
BASE_CONFIG = {
'input_size': 3072,
'hidden_sizes': [256, 128],
'num_classes': 10,
'use_batchnorm': False,
'dropout_rate': 0.05,
'init_method': 'kaiming'
}
print("\nStarting with: ReLU + Adam + Cosine + Kaiming")
print("Now we ADD regularization and see its effect ")
FINAL_BASE_CONFIG = {
**BASE_CONFIG
}
# Remove keys we'll vary in the loop
FINAL_BASE_CONFIG.pop('dropout_rate', None)
FINAL_BASE_CONFIG.pop('use_batchnorm', None)
regularization_configs = [
(0.0, False, 0, 'Baseline (No Regularization)'),
(0, False, 1e-4, '+ Weight Decay'),
(0.1, False, 1e-4, '+ Dropout + Weight Decay')
]
reg_results = {}
for dropout, batchnorm, weight_decay, name in regularization_configs:
print(f"\n{'='*70}")
print(f"Configuration: {name}")
print(f"{'='*70}")
model = FlexibleMLP(
**FINAL_BASE_CONFIG,
dropout_rate=dropout,
use_batchnorm=batchnorm
).to(device)
print(f"Dropout: {dropout}, BatchNorm: {batchnorm}, Weight Decay: {weight_decay}")
print(f"Parameters: {model.count_parameters():,}")
history = train_and_evaluate(
model, trainloader, testloader,
epochs=20,
lr=0.001,
optimizer_name='adam',
scheduler_type='cosine',
weight_decay=weight_decay,
verbose=True
)
reg_results[name] = history
# Visualize incremental improvements
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
fig.suptitle('Incremental Regularization: Building the Ultimate Model',
fontsize=16, fontweight='bold')
colors = ['black', 'red', 'green']
linewidths = [2, 2, 2, 3]
for i, (dropout, batchnorm, weight_decay, name) in enumerate(regularization_configs):
ax1.plot(reg_results[name]['train_loss'],
marker='o', label=name, color=colors[i],
linewidth=linewidths[i])
ax2.plot(reg_results[name]['test_acc'],
marker='s', label=name, color=colors[i],
linewidth=linewidths[i])
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('Training Loss', fontsize=12)
ax1.set_title('Training Loss', fontweight='bold')
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('Test Accuracy (%)', fontsize=12)
ax2.set_title('Test Accuracy', fontweight='bold')
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('incremental_regularization.png', dpi=150, bbox_inches='tight')
plt.show()
======================================================================
EXPERIMENT 5: Regularization - Building the Ultimate Model
======================================================================
Starting with: ReLU + Adam + Cosine + Kaiming
Now we ADD regularization and see its effect
======================================================================
Configuration: Baseline (No Regularization)
======================================================================
Dropout: 0.0, BatchNorm: False, Weight Decay: 0
Parameters: 820,874
Epoch 1/20: 100%|██████████| 391/391 [00:20<00:00, 19.19it/s, loss=1.6235, acc=40.89%]
Epoch 1/20 | Train Loss: 1.6896 | Train Acc: 40.89% | Test Loss: 1.5516 | Test Acc: 45.94%
Epoch 2/20: 100%|██████████| 391/391 [00:21<00:00, 18.51it/s, loss=1.3251, acc=49.04%]
Epoch 2/20 | Train Loss: 1.4549 | Train Acc: 49.04% | Test Loss: 1.4606 | Test Acc: 48.96%
Epoch 3/20: 100%|██████████| 391/391 [00:21<00:00, 18.03it/s, loss=1.3317, acc=53.19%]
Epoch 3/20 | Train Loss: 1.3386 | Train Acc: 53.19% | Test Loss: 1.4339 | Test Acc: 50.09%
Epoch 4/20: 100%|██████████| 391/391 [00:20<00:00, 18.80it/s, loss=1.0917, acc=56.17%]
Epoch 4/20 | Train Loss: 1.2487 | Train Acc: 56.17% | Test Loss: 1.3991 | Test Acc: 51.51%
Epoch 5/20: 100%|██████████| 391/391 [00:20<00:00, 19.06it/s, loss=1.0901, acc=58.85%]
Epoch 5/20 | Train Loss: 1.1704 | Train Acc: 58.85% | Test Loss: 1.4260 | Test Acc: 50.73%
Epoch 6/20: 100%|██████████| 391/391 [00:21<00:00, 17.85it/s, loss=1.3054, acc=61.76%]
Epoch 6/20 | Train Loss: 1.0925 | Train Acc: 61.76% | Test Loss: 1.3975 | Test Acc: 52.25%
Epoch 7/20: 100%|██████████| 391/391 [00:22<00:00, 17.67it/s, loss=1.0204, acc=64.17%]
Epoch 7/20 | Train Loss: 1.0228 | Train Acc: 64.17% | Test Loss: 1.3994 | Test Acc: 52.80%
Epoch 8/20: 100%|██████████| 391/391 [00:20<00:00, 19.05it/s, loss=0.8389, acc=66.74%]
Epoch 8/20 | Train Loss: 0.9461 | Train Acc: 66.74% | Test Loss: 1.4232 | Test Acc: 52.78%
Epoch 9/20: 100%|██████████| 391/391 [00:20<00:00, 18.97it/s, loss=0.9570, acc=69.51%]
Epoch 9/20 | Train Loss: 0.8736 | Train Acc: 69.51% | Test Loss: 1.4357 | Test Acc: 53.25%
Epoch 10/20: 100%|██████████| 391/391 [00:22<00:00, 17.24it/s, loss=0.9352, acc=72.22%]
Epoch 10/20 | Train Loss: 0.7999 | Train Acc: 72.22% | Test Loss: 1.4585 | Test Acc: 52.93%
Epoch 11/20: 100%|██████████| 391/391 [00:22<00:00, 17.71it/s, loss=0.6054, acc=74.98%]
Epoch 11/20 | Train Loss: 0.7266 | Train Acc: 74.98% | Test Loss: 1.4930 | Test Acc: 53.24%
Epoch 12/20: 100%|██████████| 391/391 [00:21<00:00, 18.49it/s, loss=0.6018, acc=77.42%]
Epoch 12/20 | Train Loss: 0.6611 | Train Acc: 77.42% | Test Loss: 1.5164 | Test Acc: 53.89%
Epoch 13/20: 100%|██████████| 391/391 [00:20<00:00, 18.98it/s, loss=0.7101, acc=79.72%]
Epoch 13/20 | Train Loss: 0.5974 | Train Acc: 79.72% | Test Loss: 1.5548 | Test Acc: 53.35%
Epoch 14/20: 100%|██████████| 391/391 [00:22<00:00, 17.74it/s, loss=0.4742, acc=82.21%]
Epoch 14/20 | Train Loss: 0.5422 | Train Acc: 82.21% | Test Loss: 1.5913 | Test Acc: 53.13%
Epoch 15/20: 100%|██████████| 391/391 [00:21<00:00, 17.79it/s, loss=0.5055, acc=84.09%]
Epoch 15/20 | Train Loss: 0.4954 | Train Acc: 84.09% | Test Loss: 1.6039 | Test Acc: 53.75%
Epoch 16/20: 100%|██████████| 391/391 [00:20<00:00, 19.22it/s, loss=0.5160, acc=85.84%]
Epoch 16/20 | Train Loss: 0.4554 | Train Acc: 85.84% | Test Loss: 1.6213 | Test Acc: 53.99%
Epoch 17/20: 100%|██████████| 391/391 [00:21<00:00, 18.49it/s, loss=0.4454, acc=87.25%]
Epoch 17/20 | Train Loss: 0.4254 | Train Acc: 87.25% | Test Loss: 1.6372 | Test Acc: 53.85%
Epoch 18/20: 100%|██████████| 391/391 [00:22<00:00, 17.44it/s, loss=0.5767, acc=88.12%]
Epoch 18/20 | Train Loss: 0.4041 | Train Acc: 88.12% | Test Loss: 1.6482 | Test Acc: 53.76%
Epoch 19/20: 100%|██████████| 391/391 [00:21<00:00, 17.87it/s, loss=0.5070, acc=88.76%]
Epoch 19/20 | Train Loss: 0.3890 | Train Acc: 88.76% | Test Loss: 1.6535 | Test Acc: 53.78%
Epoch 20/20: 100%|██████████| 391/391 [00:20<00:00, 19.03it/s, loss=0.3368, acc=89.21%]
Epoch 20/20 | Train Loss: 0.3805 | Train Acc: 89.21% | Test Loss: 1.6540 | Test Acc: 53.85%
======================================================================
Configuration: + Weight Decay
======================================================================
Dropout: 0, BatchNorm: False, Weight Decay: 0.0001
Parameters: 820,874
Epoch 1/20: 100%|██████████| 391/391 [00:21<00:00, 18.29it/s, loss=1.6826, acc=40.84%]
Epoch 1/20 | Train Loss: 1.6845 | Train Acc: 40.84% | Test Loss: 1.5621 | Test Acc: 44.25%
Epoch 2/20: 100%|██████████| 391/391 [00:22<00:00, 17.33it/s, loss=1.2410, acc=49.05%]
Epoch 2/20 | Train Loss: 1.4509 | Train Acc: 49.05% | Test Loss: 1.4735 | Test Acc: 47.21%
Epoch 3/20: 100%|██████████| 391/391 [00:22<00:00, 17.44it/s, loss=1.4410, acc=52.91%]
Epoch 3/20 | Train Loss: 1.3419 | Train Acc: 52.91% | Test Loss: 1.4513 | Test Acc: 48.64%
Epoch 4/20: 100%|██████████| 391/391 [00:20<00:00, 18.76it/s, loss=1.4627, acc=55.92%]
Epoch 4/20 | Train Loss: 1.2564 | Train Acc: 55.92% | Test Loss: 1.4080 | Test Acc: 50.32%
Epoch 5/20: 100%|██████████| 391/391 [00:21<00:00, 18.15it/s, loss=1.2028, acc=58.47%]
Epoch 5/20 | Train Loss: 1.1816 | Train Acc: 58.47% | Test Loss: 1.3921 | Test Acc: 51.74%
Epoch 6/20: 100%|██████████| 391/391 [00:22<00:00, 17.58it/s, loss=1.0330, acc=61.07%]
Epoch 6/20 | Train Loss: 1.1112 | Train Acc: 61.07% | Test Loss: 1.4016 | Test Acc: 51.46%
Epoch 7/20: 100%|██████████| 391/391 [00:22<00:00, 17.41it/s, loss=1.0136, acc=63.43%]
Epoch 7/20 | Train Loss: 1.0457 | Train Acc: 63.43% | Test Loss: 1.4023 | Test Acc: 52.31%
Epoch 8/20: 100%|██████████| 391/391 [00:22<00:00, 17.72it/s, loss=0.9316, acc=65.88%]
Epoch 8/20 | Train Loss: 0.9736 | Train Acc: 65.88% | Test Loss: 1.4011 | Test Acc: 52.68%
Epoch 9/20: 100%|██████████| 391/391 [00:20<00:00, 18.95it/s, loss=1.0962, acc=68.31%]
Epoch 9/20 | Train Loss: 0.9010 | Train Acc: 68.31% | Test Loss: 1.4006 | Test Acc: 52.91%
Epoch 10/20: 100%|██████████| 391/391 [00:21<00:00, 17.91it/s, loss=0.6294, acc=70.88%]
Epoch 10/20 | Train Loss: 0.8341 | Train Acc: 70.88% | Test Loss: 1.4269 | Test Acc: 52.99%
Epoch 11/20: 100%|██████████| 391/391 [00:22<00:00, 17.40it/s, loss=0.7744, acc=73.70%]
Epoch 11/20 | Train Loss: 0.7627 | Train Acc: 73.70% | Test Loss: 1.4654 | Test Acc: 53.12%
Epoch 12/20: 100%|██████████| 391/391 [00:22<00:00, 17.71it/s, loss=0.5661, acc=76.04%]
Epoch 12/20 | Train Loss: 0.6983 | Train Acc: 76.04% | Test Loss: 1.4840 | Test Acc: 53.20%
Epoch 13/20: 100%|██████████| 391/391 [00:20<00:00, 18.83it/s, loss=0.6619, acc=78.51%]
Epoch 13/20 | Train Loss: 0.6374 | Train Acc: 78.51% | Test Loss: 1.4798 | Test Acc: 53.22%
Epoch 14/20: 100%|██████████| 391/391 [00:21<00:00, 18.20it/s, loss=0.5115, acc=80.88%]
Epoch 14/20 | Train Loss: 0.5794 | Train Acc: 80.88% | Test Loss: 1.5187 | Test Acc: 53.28%
Epoch 15/20: 100%|██████████| 391/391 [00:21<00:00, 17.78it/s, loss=0.3951, acc=82.85%]
Epoch 15/20 | Train Loss: 0.5329 | Train Acc: 82.85% | Test Loss: 1.5260 | Test Acc: 53.77%
Epoch 16/20: 100%|██████████| 391/391 [00:21<00:00, 18.04it/s, loss=0.5081, acc=84.72%]
Epoch 16/20 | Train Loss: 0.4913 | Train Acc: 84.72% | Test Loss: 1.5495 | Test Acc: 53.65%
Epoch 17/20: 100%|██████████| 391/391 [00:20<00:00, 19.01it/s, loss=0.4259, acc=86.14%]
Epoch 17/20 | Train Loss: 0.4611 | Train Acc: 86.14% | Test Loss: 1.5540 | Test Acc: 53.76%
Epoch 18/20: 100%|██████████| 391/391 [00:21<00:00, 18.46it/s, loss=0.4307, acc=87.10%]
Epoch 18/20 | Train Loss: 0.4373 | Train Acc: 87.10% | Test Loss: 1.5655 | Test Acc: 53.87%
Epoch 19/20: 100%|██████████| 391/391 [00:22<00:00, 17.61it/s, loss=0.5854, acc=87.83%]
Epoch 19/20 | Train Loss: 0.4218 | Train Acc: 87.83% | Test Loss: 1.5677 | Test Acc: 53.89%
Epoch 20/20: 100%|██████████| 391/391 [00:21<00:00, 17.91it/s, loss=0.5386, acc=88.31%]
Epoch 20/20 | Train Loss: 0.4129 | Train Acc: 88.31% | Test Loss: 1.5690 | Test Acc: 53.82%
======================================================================
Configuration: + Dropout + Weight Decay
======================================================================
Dropout: 0.1, BatchNorm: False, Weight Decay: 0.0001
Parameters: 820,874
Epoch 1/20: 100%|██████████| 391/391 [00:20<00:00, 18.63it/s, loss=1.6987, acc=37.13%]
Epoch 1/20 | Train Loss: 1.7798 | Train Acc: 37.13% | Test Loss: 1.5854 | Test Acc: 43.47%
Epoch 2/20: 100%|██████████| 391/391 [00:21<00:00, 18.42it/s, loss=1.4010, acc=44.94%]
Epoch 2/20 | Train Loss: 1.5563 | Train Acc: 44.94% | Test Loss: 1.4966 | Test Acc: 47.06%
Epoch 3/20: 100%|██████████| 391/391 [00:22<00:00, 17.34it/s, loss=1.3936, acc=48.36%]
Epoch 3/20 | Train Loss: 1.4644 | Train Acc: 48.36% | Test Loss: 1.4369 | Test Acc: 49.11%
Epoch 4/20: 100%|██████████| 391/391 [00:22<00:00, 17.42it/s, loss=1.2958, acc=50.58%]
Epoch 4/20 | Train Loss: 1.3915 | Train Acc: 50.58% | Test Loss: 1.4049 | Test Acc: 50.63%
Epoch 5/20: 100%|██████████| 391/391 [00:21<00:00, 18.12it/s, loss=1.4376, acc=52.81%]
Epoch 5/20 | Train Loss: 1.3340 | Train Acc: 52.81% | Test Loss: 1.3779 | Test Acc: 51.28%
Epoch 6/20: 100%|██████████| 391/391 [00:21<00:00, 18.35it/s, loss=1.2550, acc=54.47%]
Epoch 6/20 | Train Loss: 1.2850 | Train Acc: 54.47% | Test Loss: 1.3595 | Test Acc: 52.55%
Epoch 7/20: 100%|██████████| 391/391 [00:22<00:00, 17.60it/s, loss=1.2580, acc=56.12%]
Epoch 7/20 | Train Loss: 1.2371 | Train Acc: 56.12% | Test Loss: 1.3414 | Test Acc: 52.64%
Epoch 8/20: 100%|██████████| 391/391 [00:23<00:00, 16.97it/s, loss=1.0141, acc=57.80%]
Epoch 8/20 | Train Loss: 1.1877 | Train Acc: 57.80% | Test Loss: 1.3316 | Test Acc: 53.47%
Epoch 9/20: 100%|██████████| 391/391 [00:22<00:00, 17.42it/s, loss=1.2093, acc=59.23%]
Epoch 9/20 | Train Loss: 1.1439 | Train Acc: 59.23% | Test Loss: 1.3323 | Test Acc: 53.83%
Epoch 10/20: 100%|██████████| 391/391 [00:21<00:00, 18.07it/s, loss=1.1602, acc=60.91%]
Epoch 10/20 | Train Loss: 1.0956 | Train Acc: 60.91% | Test Loss: 1.3217 | Test Acc: 53.95%
Epoch 11/20: 100%|██████████| 391/391 [00:21<00:00, 18.41it/s, loss=1.0554, acc=62.55%]
Epoch 11/20 | Train Loss: 1.0524 | Train Acc: 62.55% | Test Loss: 1.3142 | Test Acc: 54.32%
Epoch 12/20: 100%|██████████| 391/391 [00:22<00:00, 17.03it/s, loss=0.9929, acc=64.00%]
Epoch 12/20 | Train Loss: 1.0068 | Train Acc: 64.00% | Test Loss: 1.3242 | Test Acc: 54.26%
Epoch 13/20: 100%|██████████| 391/391 [00:22<00:00, 17.05it/s, loss=1.0084, acc=65.10%]
Epoch 13/20 | Train Loss: 0.9715 | Train Acc: 65.10% | Test Loss: 1.3103 | Test Acc: 54.63%
Epoch 14/20: 100%|██████████| 391/391 [00:21<00:00, 18.08it/s, loss=0.9808, acc=66.67%]
Epoch 14/20 | Train Loss: 0.9263 | Train Acc: 66.67% | Test Loss: 1.3137 | Test Acc: 55.07%
Epoch 15/20: 100%|██████████| 391/391 [00:21<00:00, 18.56it/s, loss=0.9117, acc=68.10%]
Epoch 15/20 | Train Loss: 0.8913 | Train Acc: 68.10% | Test Loss: 1.2931 | Test Acc: 55.57%
Epoch 16/20: 100%|██████████| 391/391 [00:21<00:00, 17.99it/s, loss=0.9118, acc=68.95%]
Epoch 16/20 | Train Loss: 0.8625 | Train Acc: 68.95% | Test Loss: 1.3006 | Test Acc: 55.48%
Epoch 17/20: 100%|██████████| 391/391 [00:22<00:00, 17.35it/s, loss=0.8459, acc=70.17%]
Epoch 17/20 | Train Loss: 0.8408 | Train Acc: 70.17% | Test Loss: 1.2991 | Test Acc: 55.83%
Epoch 18/20: 100%|██████████| 391/391 [00:22<00:00, 17.60it/s, loss=0.7303, acc=70.85%]
Epoch 18/20 | Train Loss: 0.8200 | Train Acc: 70.85% | Test Loss: 1.2978 | Test Acc: 55.88%
Epoch 19/20: 100%|██████████| 391/391 [00:21<00:00, 18.58it/s, loss=0.8023, acc=71.20%]
Epoch 19/20 | Train Loss: 0.8062 | Train Acc: 71.20% | Test Loss: 1.2975 | Test Acc: 56.02%
Epoch 20/20: 100%|██████████| 391/391 [00:21<00:00, 18.34it/s, loss=0.7969, acc=71.60%]
Epoch 20/20 | Train Loss: 0.7978 | Train Acc: 71.60% | Test Loss: 1.2983 | Test Acc: 56.18%